从零开始实现弹性网络回归
先决条件:
- 线性回归
- 梯度下降
- 套索和岭回归
介绍:
Elastic-Net 回归是线性回归的修改,它共享相同的预测假设函数。线性回归的成本函数由J表示。

Here, m is the total number of training examples in the dataset.
h(x(i)) represents the hypothetical function for prediction.
y(i) represents the value of target variable for ith training example.
线性回归存在过拟合问题,无法处理共线数据。当数据集中有许多特征,甚至其中一些与预测模型无关时。这使得模型更加复杂,对测试集的预测过于不准确(或过度拟合)。这种具有高方差的模型不能对新数据进行泛化。因此,为了处理这些问题,我们同时包含 L-2 和 L-1 范数正则化,以同时获得 Ridge 和 Lasso 的好处。结果模型比 Lasso 具有更好的预测能力。它执行特征选择,也使假设更简单。 Elastic-Net 回归的修正成本函数如下所示:
![\frac{1}{m}\left[\sum_{l=1}^{m}\left(y^{(i)}-h\left(x^{(i)}\right)\right)^{2}+\lambda_{1} \sum_{j=1}^{n} w_{j}+\lambda_{2} \sum_{j=1}^{n} w_{j}^{2}\right]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Implementation_of_Elastic_Net_Regression_From_Scratch_1.png "由 QuickLaTeX.com 渲染")
Here, w(j) represents the weight for jth feature.
n is the number of features in the dataset.
lambda1 is the regularization strength for L-1 norm.
lambda2 is the regularization strength for L-2 norm.数学直觉:
在其成本函数的梯度下降优化过程中,添加 L-2 惩罚项导致模型的权重降低到接近于零。由于权重的惩罚,假设变得更简单、更通用,并且不太容易过度拟合。添加了接近零或零的 L1 惩罚权重。那些缩小到零的权重消除了假设函数中存在的特征。因此,不相关的特征不参与预测模型。权重的这种惩罚使假设更具预测性,从而促进了稀疏性(具有少量参数的模型)。
调整 lambda1 和 lamda2 值的不同情况。
- 如果 lambda1 和 lambda2 设置为 0,则 Elastic-Net 回归等于线性回归。
- 如果 lambda1 设置为 0,则 Elastic-Net 回归等于岭回归。
- 如果 lambda2 设置为 0,则 Elastic-Net 回归等于 Lasso 回归。
- 如果将 lambda1 和 lambda2 设置为无穷大,则所有权重都缩小为零
因此,我们应该将 lambda1 和 lambda2 设置在 0 和无穷大之间。
执行:
此实现中使用的数据集可以从链接下载。
它有 2 列——“ YearsExperience ”和“ Salary ”,用于一家公司的 30 名员工。因此,在此,我们将训练一个 Elastic-Net Regression 模型来学习每个员工的工作年限与他们各自的薪水之间的相关性。一旦模型训练好,我们就可以根据员工多年的经验来预测他的薪水。
代码:
# Importing libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Elastic Net Regression
class ElasticRegression() :
def __init__( self, learning_rate, iterations, l1_penality, l2_penality ) :
self.learning_rate = learning_rate
self.iterations = iterations
self.l1_penality = l1_penality
self.l2_penality = l2_penality
# Function for model training
def fit( self, X, Y ) :
# no_of_training_examples, no_of_features
self.m, self.n = X.shape
# weight initialization
self.W = np.zeros( self.n )
self.b = 0
self.X = X
self.Y = Y
# gradient descent learning
for i in range( self.iterations ) :
self.update_weights()
return self
# Helper function to update weights in gradient descent
def update_weights( self ) :
Y_pred = self.predict( self.X )
# calculate gradients
dW = np.zeros( self.n )
for j in range( self.n ) :
if self.W[j] > 0 :
dW[j] = ( - ( 2 * ( self.X[:,j] ).dot( self.Y - Y_pred ) ) +
self.l1_penality + 2 * self.l2_penality * self.W[j] ) / self.m
else :
dW[j] = ( - ( 2 * ( self.X[:,j] ).dot( self.Y - Y_pred ) )
- self.l1_penality + 2 * self.l2_penality * self.W[j] ) / self.m
db = - 2 * np.sum( self.Y - Y_pred ) / self.m
# update weights
self.W = self.W - self.learning_rate * dW
self.b = self.b - self.learning_rate * db
return self
# Hypothetical function h( x )
def predict( self, X ) :
return X.dot( self.W ) + self.b
# Driver Code
def main() :
# Importing dataset
df = pd.read_csv( "salary_data.csv" )
X = df.iloc[:,:-1].values
Y = df.iloc[:,1].values
# Splitting dataset into train and test set
X_train, X_test, Y_train, Y_test = train_test_split( X, Y,
test_size = 1/3, random_state = 0 )
# Model training
model = ElasticRegression( iterations = 1000,
learning_rate = 0.01, l1_penality = 500, l2_penality = 1 )
model.fit( X_train, Y_train )
# Prediction on test set
Y_pred = model.predict( X_test )
print( "Predicted values ", np.round( Y_pred[:3], 2 ) )
print( "Real values ", Y_test[:3] )
print( "Trained W ", round( model.W[0], 2 ) )
print( "Trained b ", round( model.b, 2 ) )
# Visualization on test set
plt.scatter( X_test, Y_test, color = 'blue' )
plt.plot( X_test, Y_pred, color = 'orange' )
plt.title( 'Salary vs Experience' )
plt.xlabel( 'Years of Experience' )
plt.ylabel( 'Salary' )
plt.show()
if __name__ == "__main__" :
main()
输出:
Predicted values [ 40837.61 122887.43 65079.6 ]
Real values [ 37731 122391 57081]
Trained W 9323.84
Trained b 26851.84
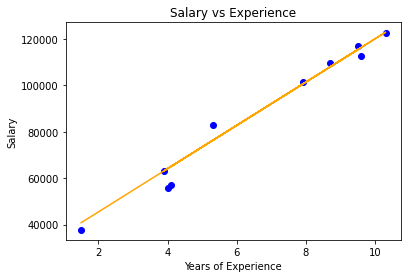
弹性网络模型可视化
注意: Elastic-Net 回归自动执行模型选择的某些部分并导致降维,这使其成为计算高效的模型。