先决条件:使用R的简单线性回归
线性回归:
它是预测分析的基本类型和常用类型,它是一种统计方法,用于对因变量和给定的一组自变量之间的关系进行建模。
这些有两种类型:
- 简单线性回归
- 多元线性回归
让我们讨论使用R的多元线性回归。
多元线性回归 :
它是线性回归的最常见形式。多元线性回归基本上描述了单个响应变量Y如何线性依赖于多个预测变量。
可以使用多重回归的基本示例如下:
- 房屋的售价可能取决于位置的理想程度,卧室的数量,浴室的数量,房屋的建造年份,土地的平方英尺以及许多其他因素。
- 孩子的身高可能取决于母亲的身高,父亲的身高,营养和环境因素。
模型参数的估计
考虑一个具有k个独立预测变量x1,x2……,xk和一个响应变量y的多元线性回归模型。 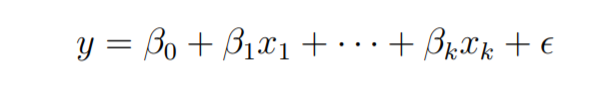
假设我们对k + 1个变量有n个观察值,并且n的变量应大于k。 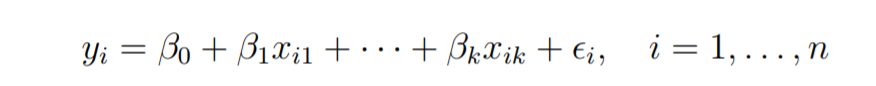
最小二乘回归的基本目标是将超平面拟合到(k + 1)维空间中,以最大程度地减少残差平方和。 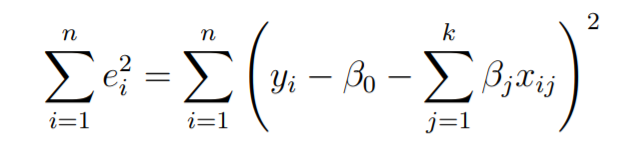
在对模型参数求导数之前,将它们设置为零,并导出参数必须满足的最小二乘法线方程。
这些方程是在向量和矩阵的帮助下制定的。
让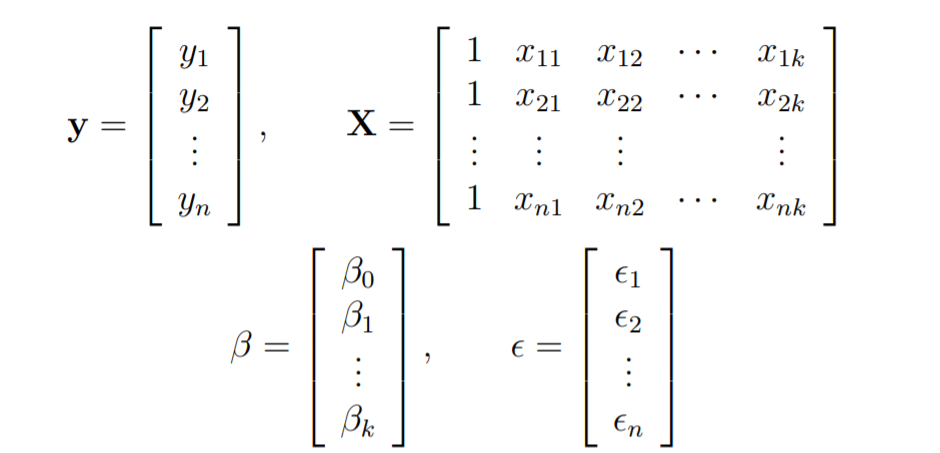
线性回归模型的编写形式如下: 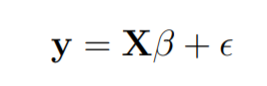
在线性回归中,最小二乘参数估计b 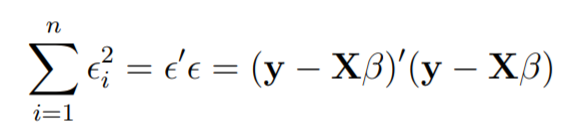
想象一下X的列是固定的,它们是特定问题的数据,并且说b是可变的。我们希望从残差平方和最小的意义上找到“最佳” b。
平方和可以为最小的最小值为零。 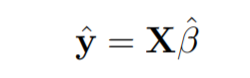
此处y是估计的响应向量。
以下R代码用于在以下数据集data2上实现多元线性回归。
数据集如下所示: 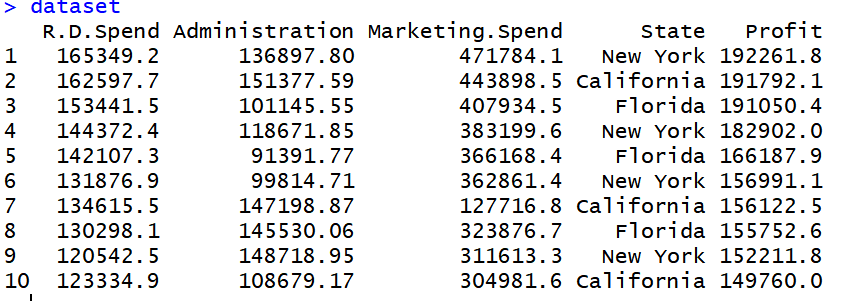
# Multiple Linear Regression
# Importing the dataset
dataset = read.csv('data2.csv')
# Encoding categorical data
dataset$State = factor(dataset$State,
levels = c('New York', 'California', 'Florida'),
labels = c(1, 2, 3))
dataset$State

# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Profit, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
# training_set = scale(training_set)
# test_set = scale(test_set)
# Fitting Multiple Linear Regression to the Training set
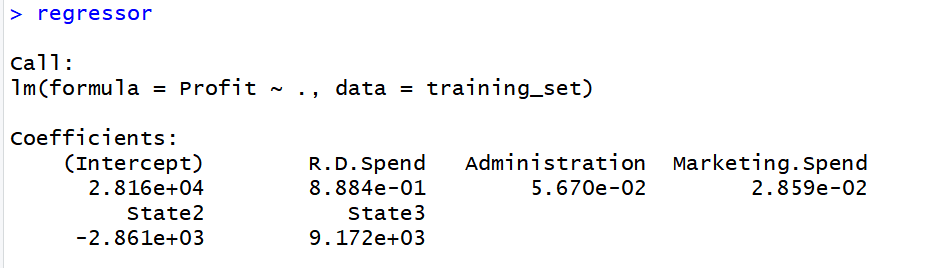
regressor = lm(formula = Profit ~ .,
data = training_set)
# Predicting the Test set results
y_pred = predict(regressor, newdata = test_set)
输出: