使用Python分析二手车的售价
如今,随着技术的进步,机器学习等技术正在许多组织中大规模使用。这些模型通常使用一组以数据集形式提供的预定义数据点。这些数据集包含特定域的过去/以前的信息。在将这些数据点输入模型之前对其进行组织非常重要。这就是我们使用数据分析的地方。如果提供给机器学习模型的数据组织得不好,它会给出错误或不希望的输出。这可能会给组织造成重大损失。因此,使用适当的数据分析非常重要。
关于数据集:
我们将在本例中使用的数据是关于汽车的。具体包含关于二手车的各种信息数据点,比如它们的价格、颜色等。这里我们需要明白,仅仅收集数据是不够的。原始数据没有用。在这里,数据分析在解锁我们需要的信息和获得对这些原始数据的新见解方面发挥着至关重要的作用。
考虑这种情况,我们的朋友 Otis 想卖掉他的车。但他不知道他的车应该卖多少钱!他想要最大化利润,但他也希望以合理的价格出售给想要拥有它的人。所以在这里,作为一名数据科学家,我们可以帮助我们的朋友 Otis。
让我们像数据科学家一样思考,明确定义他的一些问题:例如,是否有其他汽车的价格及其特性的数据?汽车的哪些特性会影响它们的价格?颜色?品牌?马力是否也会影响售价,或者可能是其他什么?
作为数据分析师或数据科学家,这些是我们可以开始思考的一些问题。要回答这些问题,我们需要一些数据。但这些数据是原始形式的。因此,我们需要先对其进行分析。数据以.csv/.data格式提供给我们
要下载此示例中使用的文件,请单击此处。提供的文件为 .data 格式。按照以下过程将 .data 文件转换为 .csv 文件。
将 .data 文件转换为 .csv 的过程:
- 打开 MS Excel
- 转到数据
- 从文本中选择
- 复选框勾选昏迷(仅)
- 保存为 .csv 到您电脑上所需的位置!
需要的模块:
- pandas: Pandas 是一个开源库,允许您在Python中执行数据操作。 Pandas 提供了一种创建、操作和整理数据的简单方法。
- numpy: Numpy 是使用Python进行科学计算的基础包。
numpy可以用作通用数据的高效多维容器。 - matplotlib: Matplotlib 是一个Python 2D 绘图库,可生成各种格式的出版质量数据。
- seaborn: Seaborn 是一个基于 matplotlib 的Python数据可视化库。 Seaborn 提供了一个高级界面,用于绘制有吸引力且信息丰富的统计图形。
- scipy: Scipy 是一个基于 Python 的数学、科学和工程开源软件生态系统。
安装这些软件包的步骤:
- 如果您使用 anaconda-jupyter/syder 或任何其他第三方软件来编写您的Python代码,请确保在您的 PC 的命令提示符中设置该软件的“脚本文件夹”的路径。
- 然后输入——pip install package-name
例子:pip install numpy - 然后安装完成后。 (确保您已连接到互联网!!)打开您的 IDE,然后导入这些包。要导入,请输入 - 导入包名称
例子:import numpy
以下代码中使用的步骤(简短描述):
- 导入包
- 设置数据文件(.csv 文件)的路径
- 查找我们的文件中是否有任何空数据或 NaN 数据。如果有,请删除它们
- 对您的数据执行各种数据清洗和数据可视化操作。这些步骤以注释的形式在每行代码旁边进行说明,以便更好地理解,因为并排查看代码比在这里完全解释代码更好,这将毫无意义。
- 获得结果!
让我们开始分析数据。
第 1 步:导入所需的模块。
# importing section
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy as sp
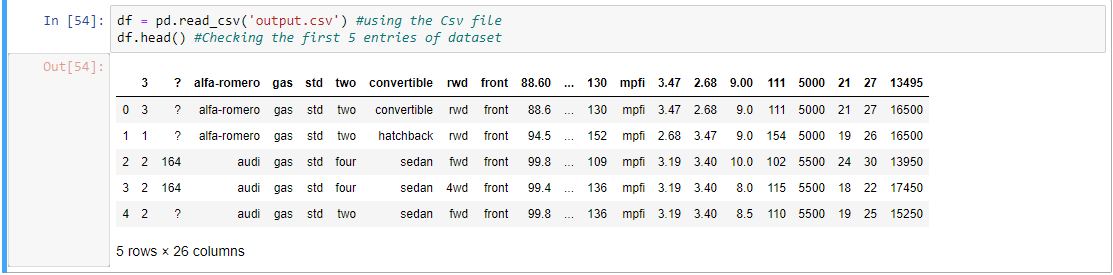
第 2 步:让我们检查数据集的前五个条目。
# using the Csv file
df = pd.read_csv('output.csv')
# Checking the first 5 entries of dataset
df.head()
输出:
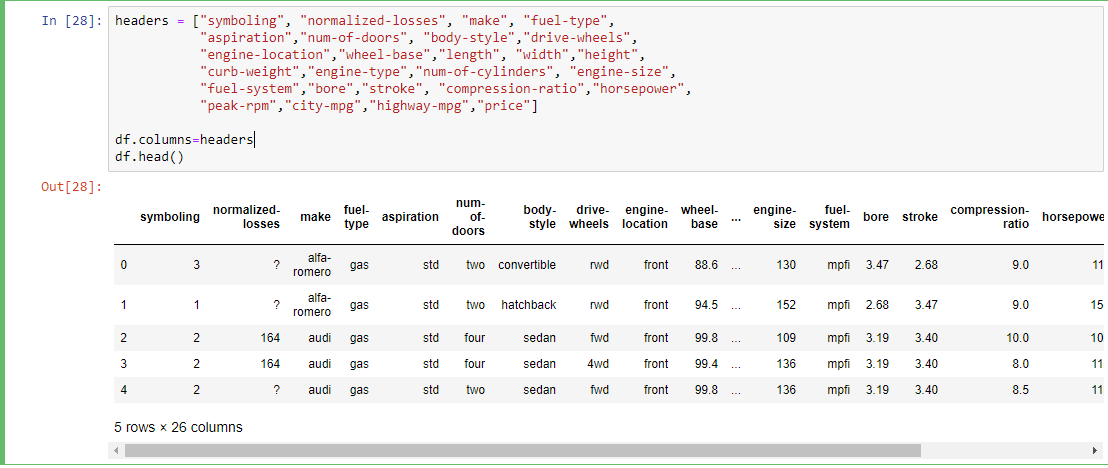
第 3 步:为我们的数据集定义标题。
headers = ["symboling", "normalized-losses", "make",
"fuel-type", "aspiration","num-of-doors",
"body-style","drive-wheels", "engine-location",
"wheel-base","length", "width","height", "curb-weight",
"engine-type","num-of-cylinders", "engine-size",
"fuel-system","bore","stroke", "compression-ratio",
"horsepower", "peak-rpm","city-mpg","highway-mpg","price"]
df.columns=headers
df.head()
输出:
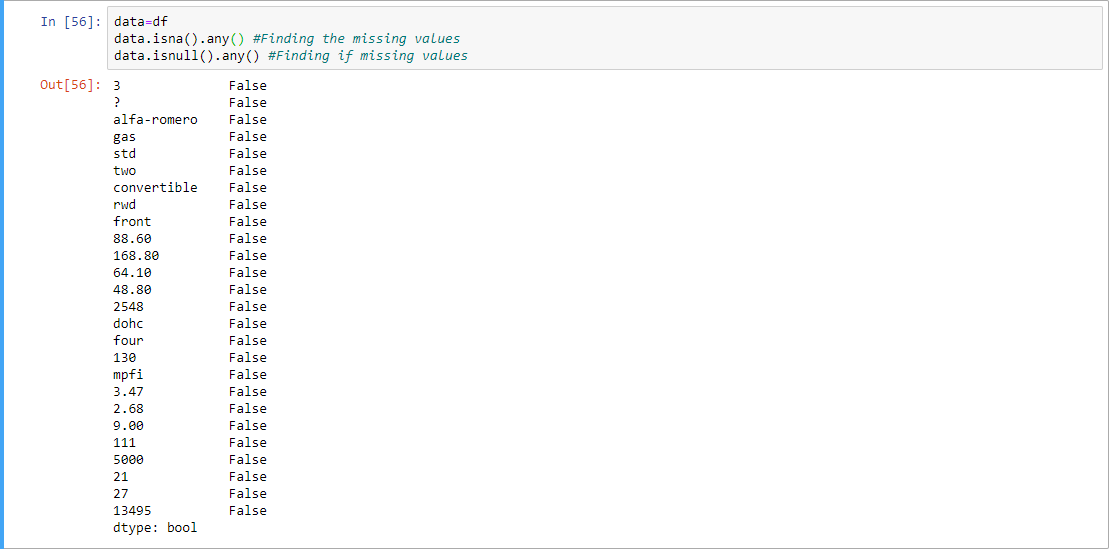
第 4 步:找到缺失值(如果有)。
data = df
# Finding the missing values
data.isna().any()
# Finding if missing values
data.isnull().any()
输出:
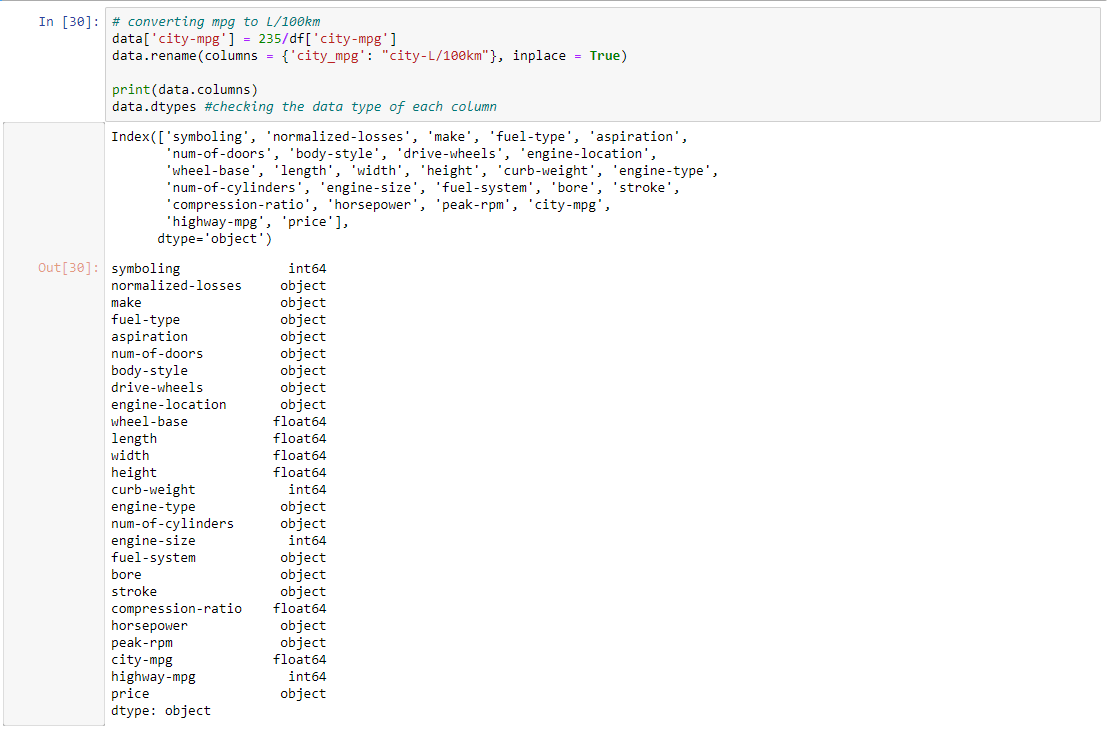
第4步:将mpg转换为L/100km,并检查每一列的数据类型。
# converting mpg to L / 100km
data['city-mpg'] = 235 / df['city-mpg']
data.rename(columns = {'city_mpg': "city-L / 100km"}, inplace = True)
print(data.columns)
# checking the data type of each column
data.dtypes
输出:
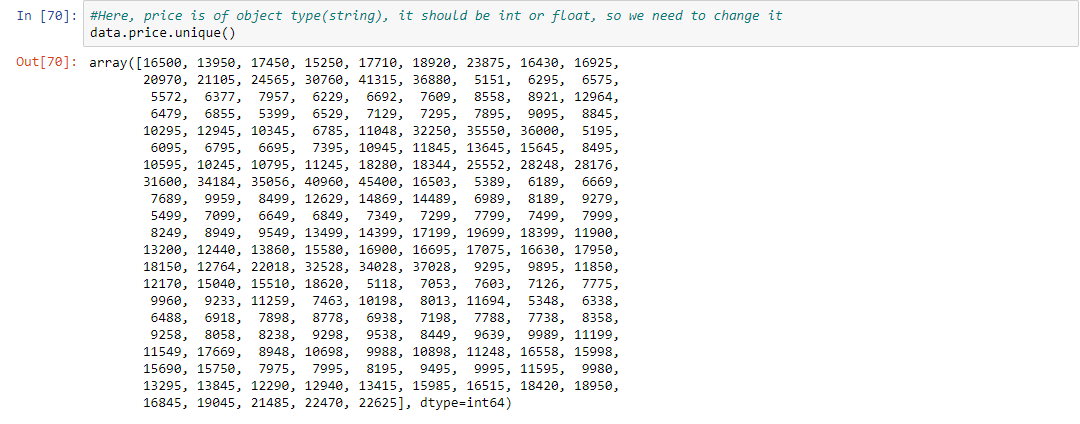
第五步:这里的价格是对象类型(字符串),它应该是int或float,所以我们需要改变它
data.price.unique()
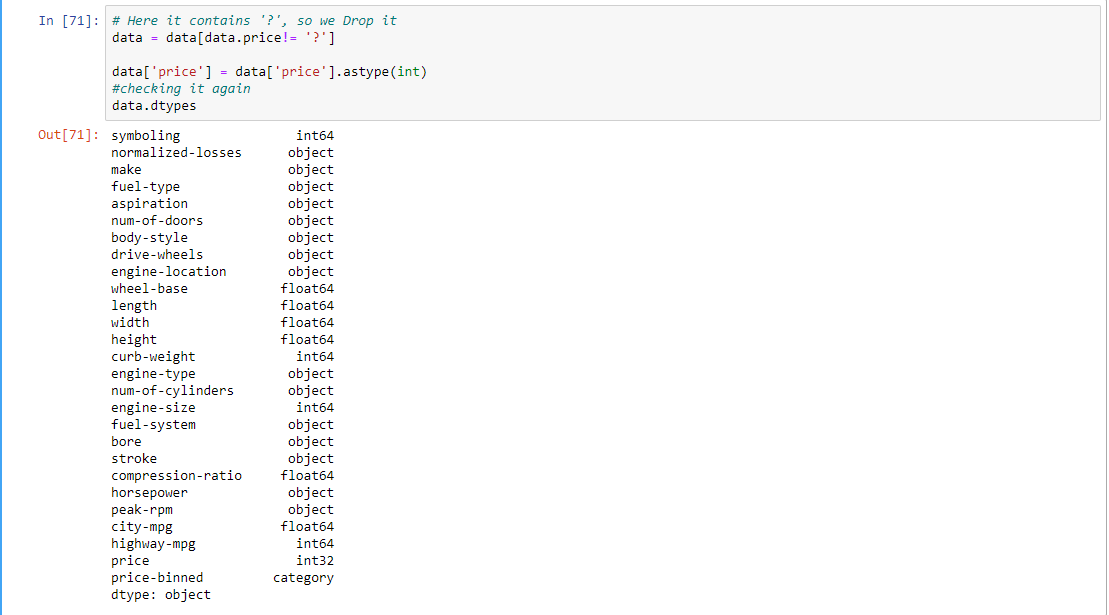
# Here it contains '?', so we Drop it
data = data[data.price != '?']
# checking it again
data.dtypes
输出:
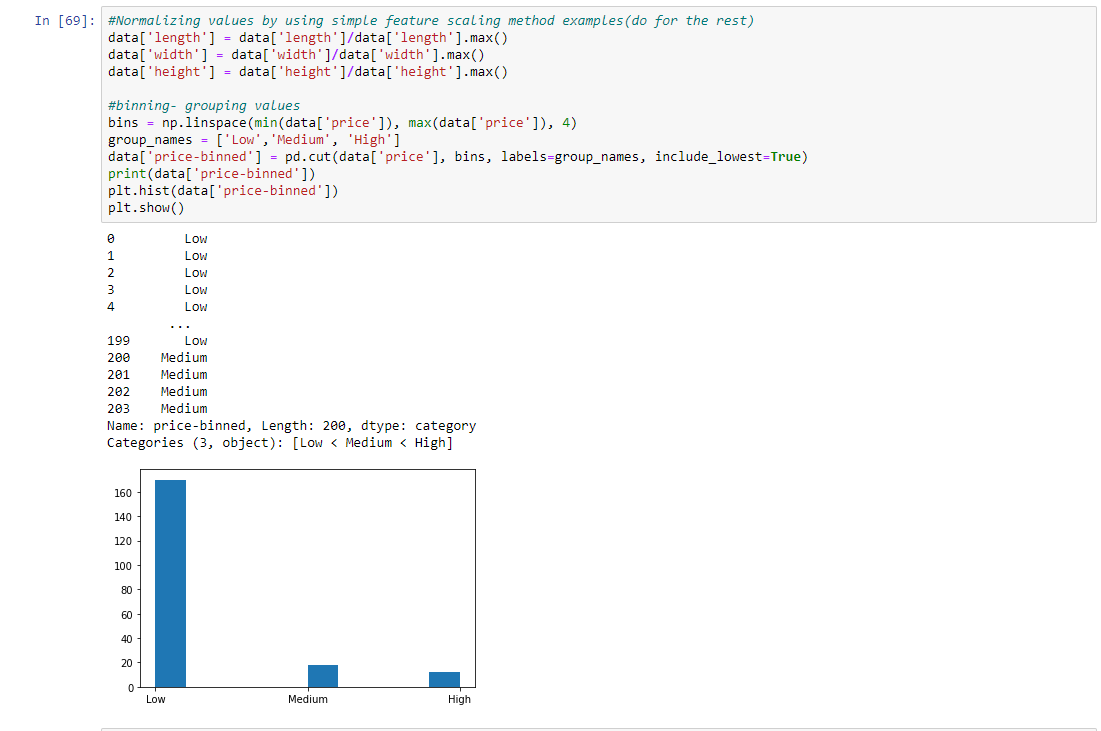
第 6 步:通过使用简单的特征缩放方法示例(为其余部分做)和分箱分组值对值进行归一化
data['length'] = data['length']/data['length'].max()
data['width'] = data['width']/data['width'].max()
data['height'] = data['height']/data['height'].max()
# binning- grouping values
bins = np.linspace(min(data['price']), max(data['price']), 4)
group_names = ['Low', 'Medium', 'High']
data['price-binned'] = pd.cut(data['price'], bins,
labels = group_names,
include_lowest = True)
print(data['price-binned'])
plt.hist(data['price-binned'])
plt.show()
输出:
第 7 步:对数值分类的数据进行描述性分析。
# categorical to numerical variables
pd.get_dummies(data['fuel-type']).head()
# descriptive analysis
# NaN are skipped
data.describe()
输出:
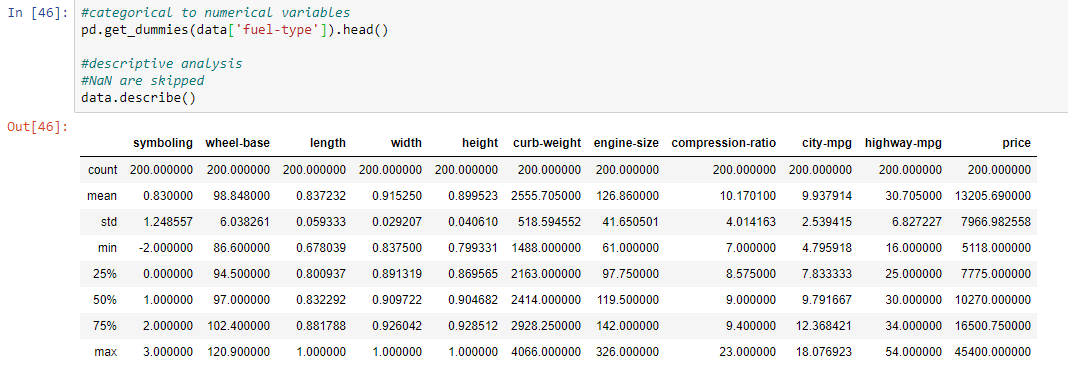
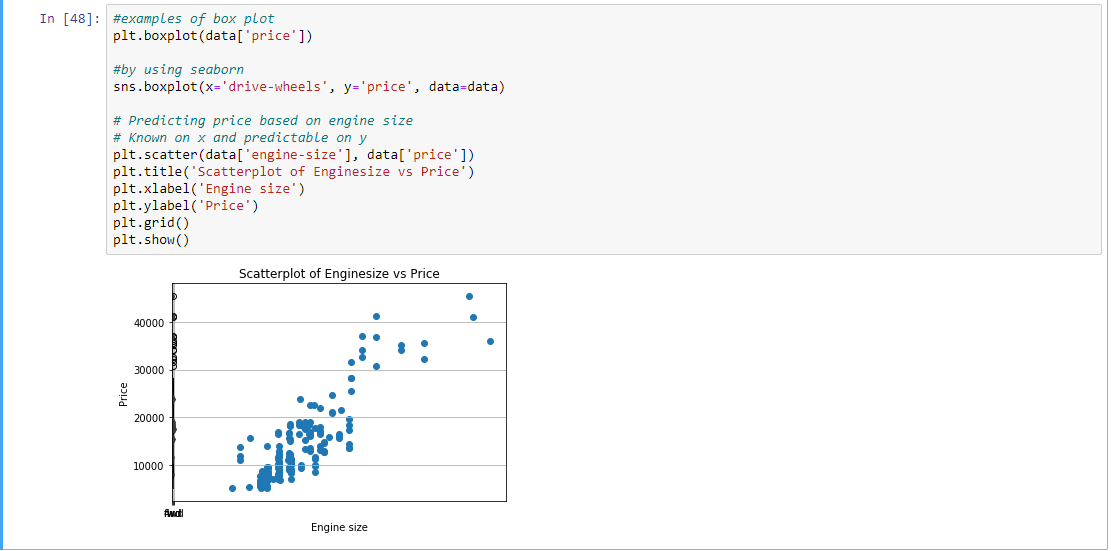
第 8 步:根据发动机尺寸的价格绘制数据。
# examples of box plot
plt.boxplot(data['price'])
# by using seaborn
sns.boxplot(x ='drive-wheels', y ='price', data = data)
# Predicting price based on engine size
# Known on x and predictable on y
plt.scatter(data['engine-size'], data['price'])
plt.title('Scatterplot of Enginesize vs Price')
plt.xlabel('Engine size')
plt.ylabel('Price')
plt.grid()
plt.show()
输出:
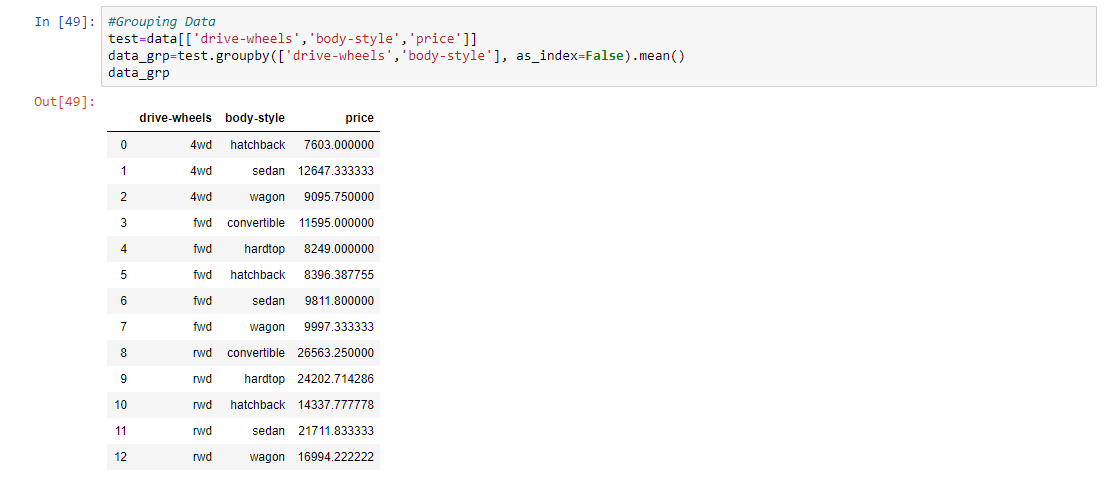
第 9 步:根据车轮、车身样式和价格对数据进行分组。
# Grouping Data
test = data[['drive-wheels', 'body-style', 'price']]
data_grp = test.groupby(['drive-wheels', 'body-style'],
as_index = False).mean()
data_grp
输出:
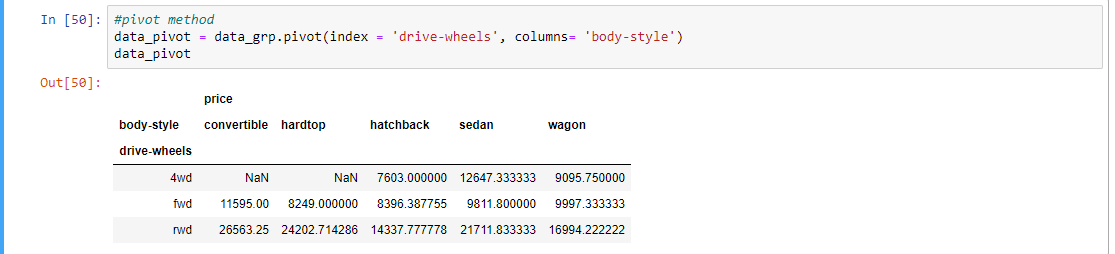
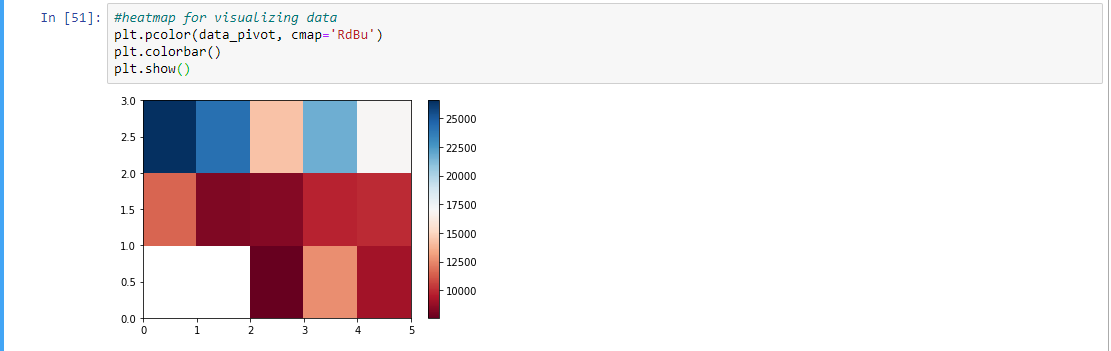
Step 10:使用pivot方法,根据pivot方法得到的数据绘制热图
# pivot method
data_pivot = data_grp.pivot(index = 'drive-wheels',
columns = 'body-style')
data_pivot
# heatmap for visualizing data
plt.pcolor(data_pivot, cmap ='RdBu')
plt.colorbar()
plt.show()
输出:
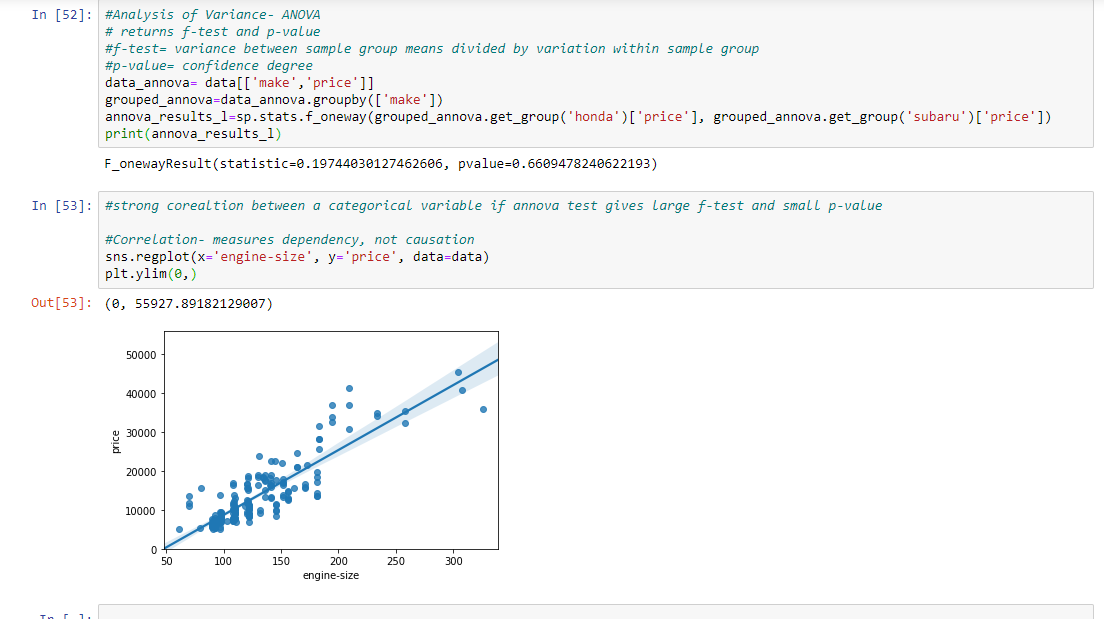
第十一步:得到最终结果,并以图表的形式展示出来。随着斜率在正方向上增加,它是一个正的线性关系。
# Analysis of Variance- ANOVA
# returns f-test and p-value
# f-test = variance between sample group means divided by
# variation within sample group
# p-value = confidence degree
data_annova = data[['make', 'price']]
grouped_annova = data_annova.groupby(['make'])
annova_results_l = sp.stats.f_oneway(
grouped_annova.get_group('honda')['price'],
grouped_annova.get_group('subaru')['price']
)
print(annova_results_l)
# strong corealtion between a categorical variable
# if annova test gives large f-test and small p-value
# Correlation- measures dependency, not causation
sns.regplot(x ='engine-size', y ='price', data = data)
plt.ylim(0, )
输出: