主成分分析基本上是一种统计过程,用于将一组可能相关的变量的观测值转换为一组线性不相关变量的值。
以这样一种方式选择每个主成分,使得它将描述大多数仍然可用的方差,并且所有这些主成分彼此正交。在所有主成分中,第一个主成分具有最大方差。
PCA的用途:
- 它用于查找数据中变量之间的相互关系。
- 它用于解释和可视化数据。
- 随着变量数量的减少,这使得进一步分析变得更加简单。
- 它通常用于可视化群体之间的遗传距离和相关性。
这些基本上是在正方形对称矩阵上执行的。它可以是平方和叉积矩阵或协方差矩阵或相关矩阵的纯和。如果个体方差相差很大,则使用相关矩阵。
PCA的目标:
- 从本质上讲,这是一个非依赖性过程,在该过程中,属性空间从大量变量减少到较少数目的因素。
- PCA基本上是降维过程,但不能保证该维数是可解释的。
- 此PCA的主要任务是从较大的集合中选择变量的子集,基于此变量,原始变量与本金的相关性最高。
主轴法: PCA基本上搜索变量的线性组合,以便我们可以从变量中提取最大方差。此过程完成后,便将其删除并搜索另一个线性组合,该组合给出了有关剩余方差的最大比例的解释,该比例主要导致正交因子。在这种方法中,我们分析了总方差。
特征向量:它是一个非零向量,在矩阵相乘后保持平行。假设x是矩阵M的维度r的特征向量,如果Mx和x平行,则维度r * r。然后我们需要求解Mx = Ax,其中x和A都未知,以获得特征向量和特征值。
在特征向量下,我们可以说主成分同时显示变量的公共方差和唯一方差。基本上,这是一种以方差为中心的方法,旨在重现总方差和与所有组成部分的相关性。主要成分基本上是原始变量的线性组合,这些线性组合按其贡献加权,以解释特定正交维度中的方差。
特征值:它基本上被称为特征根。它基本上测量了由该因素引起的所有变量的方差。特征值的比率是因素相对于变量的解释重要性的比率。如果因子较低,那么它在解释变量方面的贡献就较小。简而言之,它衡量的是该因素所占的给定数据库总数的方差量。我们可以将因子的特征值计算为所有变量的因子加载平方值之和。
现在,让我们了解使用Python的主成分分析。
要获取实现中使用的数据集,请单击此处。
步骤1:导入库
# importing required libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
步骤2:导入数据集
导入数据集并将数据集分布到X和y组件中以进行数据分析。
# importing or loading the dataset
dataset = pd.read_csv('wines.csv')
# distributing the dataset into two components X and Y
X = dataset.iloc[:, 0:13].values
y = dataset.iloc[:, 13].values
步骤3:将资料集分为训练集和测试集
# Splitting the X and Y into the
# Training set and Testing set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
步骤4:功能缩放
在培训和测试集上进行预处理,例如安装标准秤。
# performing preprocessing part
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
步骤5:应用PCA函数
将PCA函数应用于训练和测试集以进行分析。
# Applying PCA function on training
# and testing set of X component
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
explained_variance = pca.explained_variance_ratio_
步骤6:将Logistic回归拟合到训练集中
# Fitting Logistic Regression To the training set
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)

步骤7:预测测试集结果
# Predicting the test set result using
# predict function under LogisticRegression
y_pred = classifier.predict(X_test)
步骤8:制作混淆矩阵
# making confusion matrix between
# test set of Y and predicted value.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
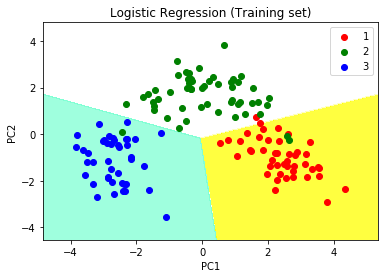
步骤9:预测训练集结果
# Predicting the training set
# result through scatter plot
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),
X2.ravel()]).T).reshape(X1.shape), alpha = 0.75,
cmap = ListedColormap(('yellow', 'white', 'aquamarine')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('PC1') # for Xlabel
plt.ylabel('PC2') # for Ylabel
plt.legend() # to show legend
# show scatter plot
plt.show()
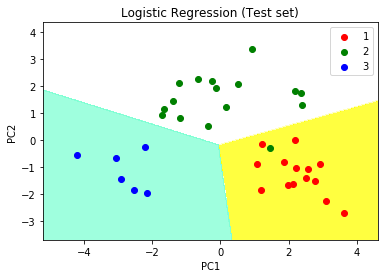
 步骤10:可视化测试集结果
步骤10:可视化测试集结果
# Visualising the Test set results through scatter plot
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),
X2.ravel()]).T).reshape(X1.shape), alpha = 0.75,
cmap = ListedColormap(('yellow', 'white', 'aquamarine')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
# title for scatter plot
plt.title('Logistic Regression (Test set)')
plt.xlabel('PC1') # for Xlabel
plt.ylabel('PC2') # for Ylabel
plt.legend()
# show scatter plot
plt.show()