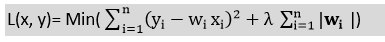- 机器学习中的逻辑回归
- 机器学习中的逻辑回归(1)
- 机器学习中的线性回归
- 机器学习中的线性回归(1)
- 机器学习中的回归与分类
- 机器学习-多项式回归(1)
- 机器学习-多项式回归
- C++中的机器学习
- 机器学习 (1)
- 机器学习中的 P 值
- C++中的机器学习(1)
- 机器学习中的 P 值(1)
- 机器学习中的简单线性回归(1)
- 机器学习中的简单线性回归
- 机器学习 python (1)
- 机器学习-主成分分析
- 机器学习-主成分分析(1)
- R 编程中的回归分析
- R 编程中的回归分析(1)
- 机器学习和预测分析之间的区别
- 机器学习和预测分析之间的区别(1)
- 站点位置数据的机器学习和分析(1)
- 站点位置数据的机器学习和分析
- 机器学习 python 代码示例
- 机器学习-多元线性回归(1)
- 机器学习-多元线性回归
- 回归和分类 |监督机器学习
- 回归和分类 |监督机器学习(1)
- 机器学习 - 任何代码示例
📅 最后修改于: 2020-09-27 01:05:39 🧑 作者: Mango
机器学习中的回归分析
回归分析是一种统计方法,用于对具有一个或多个自变量的因变量(目标变量)和自变量(预测变量)之间的关系进行建模。更具体地说,回归分析有助于我们理解在其他自变量保持固定的情况下,自变量的值对应于自变量的变化方式。它可以预测连续/实际值,例如温度,年龄,工资,价格等。
我们可以使用以下示例了解回归分析的概念:
示例:假设有一家营销公司A,该公司每年都会做各种广告并以此获得销售。以下列表显示了该公司在过去5年中制作的广告以及相应的销售额:
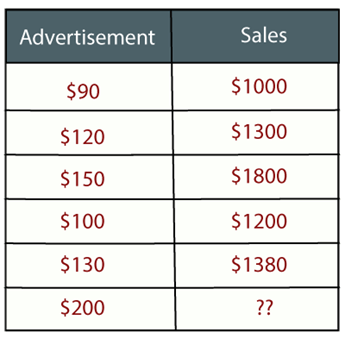
现在,该公司想要在2019年做200美元的广告,并想知道有关今年销售额的预测。因此,为了解决机器学习中的这类预测问题,我们需要回归分析。
回归是一种有监督的学习技术,有助于发现变量之间的相关性,并使我们能够基于一个或多个预测变量来预测连续输出变量。它主要用于预测,预测,时间序列建模以及确定变量之间的因果关系。
在回归中,我们在最适合给定数据点的变量之间绘制图形,使用此图形,机器学习模型可以对数据进行预测。用简单的话说,“回归显示一条线或曲线,它穿过目标预测图上的所有数据点,以使数据点和回归线之间的垂直距离最小。”数据点和线之间的距离表明模型是否已捕获牢固的关系。
回归的一些示例如下:
- 利用温度和其他因素预测降雨
- 确定市场趋势
- 预测由于皮疹驾驶造成的道路交通事故。
与回归分析有关的术语:
- 因变量:我们要预测或理解的回归分析中的主要因素称为因变量。也称为目标变量 。
- 自变量:影响因变量或用于预测因变量值的因子称为自变量,也称为预测变量 。
- 离群值:离群值是与其他观测值相比包含非常低值或非常高值的观察值。离群值可能会影响结果,因此应避免使用。
- 多重共线性:如果自变量比其他变量彼此高度相关,则这种条件称为多重共线性。它不应出现在数据集中,因为在对影响最大的变量进行排名时会产生问题。
- 欠拟合和过度拟合:如果我们的算法在训练数据集上效果很好,但在测试数据集上效果不好,那么这种问题称为“ 过度拟合” 。如果我们的算法即使在训练数据集的情况下也无法很好地执行,则这种问题称为欠拟合 。
我们为什么要使用回归分析?
如上所述,回归分析有助于预测连续变量。在现实世界中,我们需要一些未来的预测,例如天气状况,销售预测,市场趋势等,在这种情况下,我们需要一些可以更准确地进行预测的技术。因此对于这种情况,我们需要回归分析,这是一种统计方法,用于机器学习和数据科学中。以下是使用回归分析的其他一些原因:
- 回归估计目标和自变量之间的关系。
- 它用于查找数据趋势。
- 它有助于预测实际/连续值。
- 通过执行回归,我们可以自信地确定最重要的因素,最不重要的因素,以及每个因素如何影响其他因素 。
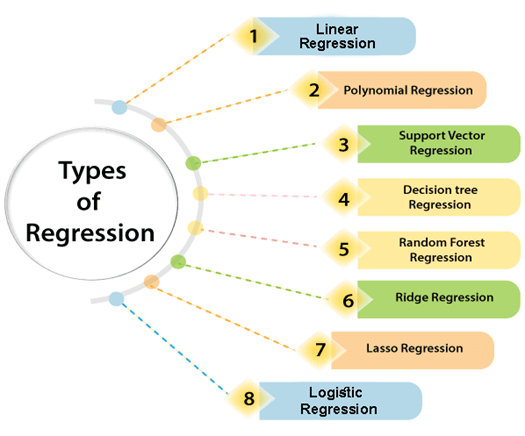
回归类型
数据科学和机器学习中使用了各种类型的回归。每种类型在不同情况下都有其重要性,但从根本上讲,所有回归方法都分析了自变量对因变量的影响。在这里,我们讨论了一些重要的回归类型,如下所示:
- 线性回归
- 逻辑回归
- 多项式回归
- 支持向量回归
- 决策树回归
- 森林随机回归
- 岭回归
- 套索回归:
线性回归:
- 线性回归是用于预测分析的统计回归方法。
- 它是非常简单易用的算法之一,可用于回归并显示连续变量之间的关系。
- 它用于解决机器学习中的回归问题。
- 线性回归显示自变量(X轴)和因变量(Y轴)之间的线性关系,因此称为线性回归。
- 如果只有一个输入变量(x),则这种线性回归称为简单线性回归 。如果输入变量不止一个,则这种线性回归称为多元线性回归 。
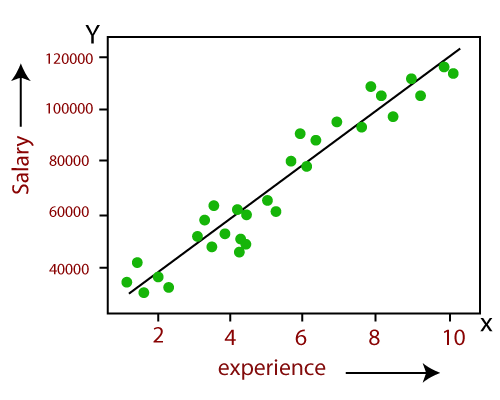
- 线性回归模型中变量之间的关系可以使用下图说明。在这里,我们根据经验的年限来预测员工的薪水。
- 以下是线性回归的数学方程式:
Y= aX+b
在这里,Y =因变量(目标变量),X =自变量(预测变量),a和b是线性系数
线性回归的一些流行应用是:
- 分析趋势和销售估算
- 薪资预测
- 房地产预测
- 到达交通中的预计到达时间。
逻辑回归:
- Logistic回归是另一种监督学习算法,用于解决分类问题。在分类问题中 ,我们具有二进制或离散格式(例如0或1)的因变量。
- Logistic回归算法适用于分类变量,例如0或1,是或否,对或错,垃圾邮件或非垃圾邮件等。
- 它是一种基于概率概念的预测分析算法。
- Logistic回归是一种回归类型,但与线性回归算法的使用方式不同。
- Logistic回归使用S型函数或logistic 函数 ,它是一个复杂的成本函数。该S形函数用于在逻辑回归中对数据建模。该函数可以表示为:

- f(x)=输出0到1之间的值。
- x =输入到函数
- e =自然对数的底数。
当我们向函数提供输入值(数据)时,它会给出S曲线,如下所示:
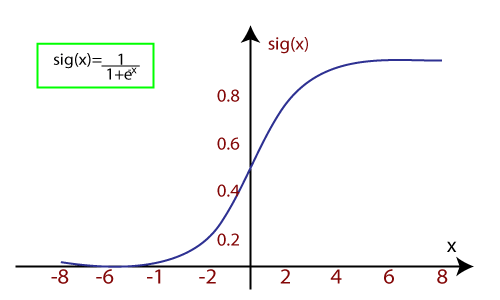
- 它使用阈值级别的概念,将阈值级别以上的值四舍五入为1,将阈值级别以下的值四舍五入为0。
逻辑回归有以下三种类型:
- 二进制(0/1,通过/失败)
- 多种(猫,狗,狮子)
- 顺序(低,中,高)
多项式回归:
- 多项式回归是一种回归类型,它使用线性模型对非线性数据集进行建模。
- 它类似于多元线性回归,但它拟合x值和y的相应条件值之间的非线性曲线。
- 假设有一个数据集,该数据集由以非线性方式出现的数据点组成,因此在这种情况下,线性回归将不会最适合这些数据点。为了涵盖这些数据点,我们需要多项式回归。
- 在多项式回归中,将原始特征转换为给定程度的多项式特征,然后使用线性模型进行建模。这意味着最好使用多项式线拟合数据点。
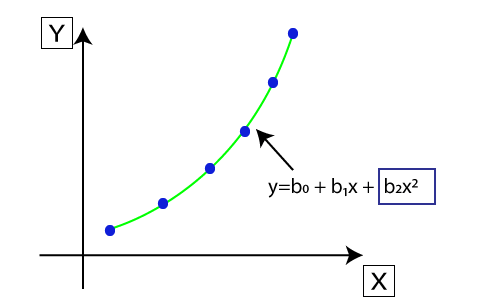
- 多项式回归方程式也从线性回归方程式衍生而来,这意味着线性回归方程式Y = b 0 + b 1 x转换为多项式回归方程式Y = b 0 + b 1 x + b 2 x 2 + b 3 x 3 +。 …. + b n x n 。
- Y是预测/目标输出,b 0 ,b 1 ,… b n是回归系数 。 x是我们的自变量/输入变量 。
- 该模型仍然是线性的,因为系数仍是二次线性的
注意:这与多元线性回归的不同之处在于,在多项式回归中,单个元素具有不同的度数,而不是具有相同度数的多个变量。
支持向量回归:
支持向量机是一种监督学习算法,可用于回归以及分类问题。因此,如果我们将其用于回归问题,则称为支持向量回归。
支持向量回归是一种适用于连续变量的回归算法。以下是支持向量回归中使用的一些关键字:
- 内核:此函数用于将低维数据映射到高维数据。
- 超平面:在一般的SVM中,它是两类之间的分隔线,但是在SVR中,这是一条线,可以帮助预测连续变量并覆盖大多数数据点。
- 边界线:边界线是与超平面分开的两条线,这为数据点创建了边距。
- 支持向量:支持向量是最接近超平面且相反类别的数据点。
在SVR中,我们总是尝试确定具有最大余量的超平面,以便在该余量中覆盖最大数量的数据点。 SVR的主要目标是考虑边界线内的最大数据点,并且超平面(最佳拟合线)必须包含最大数量的数据点。考虑下图:
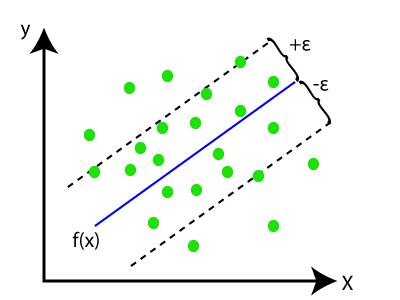
在此,蓝线称为超平面,其他两线称为边界线。
决策树回归:
- 决策树是一种监督学习算法,可用于解决分类和回归问题。
- 它可以解决分类数据和数值数据的问题
- 决策树回归构建树状结构,其中每个内部节点代表一个属性的“测试”,每个分支代表测试的结果,每个叶子节点代表最终的决策或结果。
- 从根节点/父节点(数据集)开始构建决策树,该树分为左右子节点(数据集的子集)。这些子节点进一步分为其子节点,它们本身成为这些节点的父节点。考虑下图:
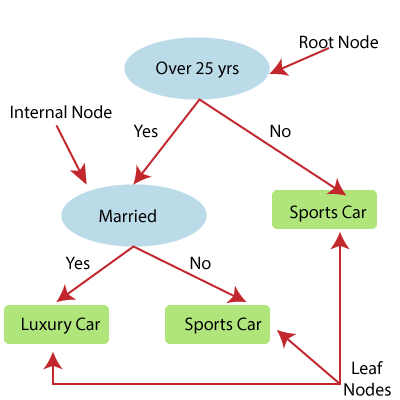
上图显示了Decision Tee回归的示例,此处,该模型正在尝试预测在跑车还是豪华车之间选择人。
- 随机森林是最强大的监督学习算法之一,能够执行回归以及分类任务。
- 随机森林回归是一种集成学习方法,它结合了多个决策树并根据每个树输出的平均值预测最终输出。组合的决策树称为基本模型,可以更正式地表示为:
- 随机森林使用集成学习的Bagging或Bootstrap聚合技术,其中聚合的决策树并行运行,并且彼此不交互。
- 借助随机森林回归,我们可以通过创建数据集的随机子集来防止模型过度拟合。

岭回归:
- Ridge回归是线性回归最可靠的版本之一,其中引入了少量偏差,以便我们可以获得更好的长期预测。
- 添加到模型的偏差量称为Ridge回归罚分 。我们可以通过将lambda乘以每个特征的权重的平方来计算该惩罚项。
- 岭回归的方程式为:
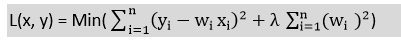
- 如果自变量之间具有较高的共线性,则一般的线性或多项式回归将失败,因此可以使用Ridge回归来解决此类问题。
- Ridge回归是一种正则化技术,可用于降低模型的复杂性。也称为L2正则化 。
- 如果参数多于样本,则有助于解决问题。
套索回归:
- 套索回归是降低模型复杂性的另一种正则化技术。
- 它与里奇回归相似,除了惩罚项仅包含绝对权重,而不是权重的平方。
- 由于它采用绝对值,因此可以将斜率缩小到0,而Ridge回归只能将其缩小到0。
- 也称为L1正则化 。拉索回归的方程式为: