使用 Web App 进行图像分类
使用 CNN 检测紧急车辆

动机:最近我参加了由 Analytics Vidhya 主办的 JanataHack:计算机视觉黑客马拉松。比赛的目的是创建一个可以区分非紧急车辆的二进制图像分类器,例如。私人拥有的车辆。来自紧急车辆(警车、救护车等)。
问题陈述:
我们需要创建一个能够区分紧急车辆和非紧急车辆的分类器。紧急车辆标记为 1,非紧急车辆标记为 0。在本文中,我将展示我创建模型的方法,该模型在 10000 个中排在第 147 位。
本文展示的模型是卷积神经网络。我试图使代码尽可能简单。读者需要对神经网络有一定的了解。
问题解决步骤:
- 加载和可视化数据
- 数据清洗
- 造型
- 迁移学习
- 参数调整
- 最终模型。
代码:加载和可视化数据
Python3
# imports
import numpy as np
import os
import matplotlib.pyplot as plt
from PIL import Image, ImageOps, ImageFilter, ImageEnhance
import pandas as pd
# importing pytorch library.
import torchvision.transforms as transforms
import torch.nn.functional as F
import torch.nn as nn
from torch.utils.data import Dataset, random_split, DataLoaderPython3
# name of the image folder
imagePaths = 'images'
# reading the train.csv file using pandas
trainImages = pd.read_csv('train.csv')
# reading the test.csv file using pandas
testImages = pd.read_csv('test.csv')
# reading the submission file using pandas
samples = pd.read_csv('sample_submission.csv')Python3
# defining train and labels list to store images and labels respectively.
train = []
labels = []
for image, label in zip(trainImages.iloc[:, 0], trainImages.iloc[:, 1]):
# create a image path and store in img_path variable
imgPath = os.path.join(imagePaths, image)
# Use PIl Image class to load the image
img = Image.open(imgPath)
# apply median filter to the image this helps in reducing noise
img = img.filter(ImageFilter.MedianFilter)
# convert the image to numpy array and store the loaded images into train
train.append(np.asarray(img))
# store the label into the labels list
labels.append(label)Python3
# create subplots using the plt.subplots function
# the number of subplots depend on the n_rows and n_cols
# all the subplots are stored in ax variables
_, ax = plt.subplots(nrows = 4, ncols = 7, figsize =(12, 12))
# iterate through the ax variable by flattening it
for index, i in enumerate(ax.flatten()):
# the imshow is used to show the image
i.imshow(train[index])
# set the title
i.set_title(index)
# this below lines makes the code better visualize.
i.set_xticks([])
i.set_yticks([])Python3
# Creating a VehicleDataset class for loading the images and labels .
# the following class needs to extend from the Dataset class
# provided by pytorch framework and implement the __len__ and __getitem__ methods.
class VehicleDataset(Dataset):
def __init__(self, csv_name, folder, transform = None, label = False):
self.label = label
self.folder = folder
print(csv_name)
self.dataframe = pd.read_csv(self.folder+'/'+csv_name+'.csv')
self.tms = transform
def __len__(self):
return len(self.dataframe)
def __getitem__(self, index):
row = self.dataframe.iloc[index]
imgIndex = row['image_names']
imageFile = self.folder + '/' + img_index
image = Image.open(image_file)
if self.label:
target = row['emergency_or_not']
if target == 0:
encode = torch.FloatTensor([1, 0])
else:
encode = torch.FloatTensor([0, 1])
return self.tms(image), encode
return self.tms(image)
# creating objects of VehicleDataset
# the deep learning models accepts the image to be in tensor format
# this is done using the transforms.ToTensor() methods
transform = transforms.Compose([transforms.ToTensor(),
])
'''
arguments:
csv_name - name of the csv file in out case train.csv
folder - folder in which the images are stored
transform - transforms the image to tensor,
label - used to differentiate between train and test set.
''''
trainDataset = VehicleDataset('train', 'images', label = True, transform = transform)Python
# the EmergencyCustomModel class defines our Neural Network
# It inherites from the ImageClassificationBase class which has helper methods
# for printing the loss and accuracy at each epochs.
class EmergencyCustomModel(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Conv2d(3, 32, kernel_size = 3, padding = 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 128, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 2),
# nn.Sigmoid(),
)
def forward(self, xb):
return self.network(xb)Python3
# defining the training method.
# the evaluation method is used to calculate validation accuracy.
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
# The fit method is used to train the model
# parameters
'''
epochs: no. of epochs the model trains
max_lr: maximum learning rate.
train_loader: here we pass the train dataset
val_loader: here we pass the val_dataset
opt_func : The learning algorithm that performs gradient descent.
model : the neural network to train on.
'''
def fit(epochs, max_lr, model, train_loader, val_loader,
weight_decay = 0, grad_clip = None, opt_func = torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up custom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay = weight_decay)
# the loop iterates from 0 to number of epochs.
# the model needs to be set in the train model by calling the model.train.
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
for batch in train_loader:
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
model.epoch_end(epoch, result)
history.append(result)
return historyPython3
# the batchSize is the number of images passes by the loader at a time.
# reduce this number if theres an out of memory error.
batchSize = 32
valPct = 0.2
# code for splitting the data
# valPct variable is used to split dataset
valSize = int(valPct * len(trainDataset))
trainSize = len(trainDataset) - valSize
trainDs, valDs = random_split(trainDataset, [trainSize, valSize])
# Creating dataloaders.
train_loader = DataLoader(trainDs, batchSize)
val_loader = DataLoader(valDs, batchSize)Python3
customModel = EmergencyCustomModel()
epochs = 10
lr = 0.01
# save the history to visualize later.
history = fit(epochs, lr, customModel, trainDl, valDl)Python3
'''
parameters:
epochs = number of epochs the model was trained on
hist = the history returned by the fit function.
'''
def plot(hist, epochs = 10):
trainLoss = []
valLoss = []
valScore = []
for i in range(epochs):
trainLoss.append(hist[i]['train_loss'])
valLoss.append(hist[i]['val_loss'])
valScore.append(hist[i]['val_score'])
plt.plot(trainLoss, label ='train_loss')
plt.plot(valLoss, label ='val_loss')
plt.legend()
plt.title('loss')
plt.figure()
plt.plot(valScore, label ='val_score')
plt.legend()
plt.title('accuracy')
# calling the function
plot(history)Python3
# to use the pretrained model we make use of the torchvision.models library
class ResNet50(ImageClassificationBase):
def __init__(self):
super().__init__()
# this following line adds the downloads the resnet50 model is it doesn't exits
# and stores it in pretrainedModle
self.pretrainedModel = models.resnet50(pretrained = True)
# since this model was trained on ImageNet data which has 1000 classes but for
# problem we have only 2 so will need to modify the final layer of the model
feature_in = self.pretrainedModel.fc.inFeatures
self.pretrainedModel.fc = nn.Linear(feature_in, 2)
def forward(self, x):
return self.pretrainedModel(x)
# Trainin the model.
# final Learning with
lr = 1e-4
epochs = 5
optFunc = torch.optim.Adam
# Here I have made use of the wd this is used as a regularization parameter
# It helps in preventing overfitting and helps our model to generalize.
bestWd = 1e-4
custom_model = to_device(ResNet50(), device)
hist = fit(epochs, lr, customModel, trainDl, valDl, bestWd, optFunc)Python3
class Densenet169(ImageClassificationBase):
def __init__(self):
super().__init__()
# the below statement is used to download and store the pretrained model.
self.pretrained_model = models.densenet169(pretrained = True)
feature_in = self.pretrained_model.classifier.in_features
self.pretrained_model.classifier = nn.Linear(feature_in, 2)
def forward(self, x):
return self.pretrained_model(x)
Training the model
# final Learning with
lr = 1e-4
epochs = 5
optFunc = torch.optim.Adam
bestWd = 1e-4
customModel2 = Densenet169()
hist = fit(epochs, lr, customModel2, trainDl, valDl, bestWd, optFunc)我们将使用:
- numpy :将图像存储到数组中,
- matplotlib :可视化图像,
- PILLOW or(PIL): 加载和转换图像的库
- Pytorch :用于我们的深度学习框架。
数据加载:
上图显示了提供给我们的数据集,训练集和测试集都存在于 images 文件夹中,训练和测试 CVS 文件包含图像的名称。
代码:
Python3
# name of the image folder
imagePaths = 'images'
# reading the train.csv file using pandas
trainImages = pd.read_csv('train.csv')
# reading the test.csv file using pandas
testImages = pd.read_csv('test.csv')
# reading the submission file using pandas
samples = pd.read_csv('sample_submission.csv')
代码:将图像加载到 numpy 数组中
Python3
# defining train and labels list to store images and labels respectively.
train = []
labels = []
for image, label in zip(trainImages.iloc[:, 0], trainImages.iloc[:, 1]):
# create a image path and store in img_path variable
imgPath = os.path.join(imagePaths, image)
# Use PIl Image class to load the image
img = Image.open(imgPath)
# apply median filter to the image this helps in reducing noise
img = img.filter(ImageFilter.MedianFilter)
# convert the image to numpy array and store the loaded images into train
train.append(np.asarray(img))
# store the label into the labels list
labels.append(label)
代码:打开和显示图像。
Python3
# create subplots using the plt.subplots function
# the number of subplots depend on the n_rows and n_cols
# all the subplots are stored in ax variables
_, ax = plt.subplots(nrows = 4, ncols = 7, figsize =(12, 12))
# iterate through the ax variable by flattening it
for index, i in enumerate(ax.flatten()):
# the imshow is used to show the image
i.imshow(train[index])
# set the title
i.set_title(index)
# this below lines makes the code better visualize.
i.set_xticks([])
i.set_yticks([])
输出:

上述单元格的输出。
现在我们将图像存储在训练中,输出类存储在标签中,我们可以继续下一步。
数据清洗
在本节中,我们将通过删除这些图像来查看未分类标签和不正确的图像样本,我的准确性将 val_score 提高了 2%。它从 94% 上升到 96%,有时甚至达到 97%。
Miss labelledImages:用于可视化数据的代码同上

错误分类的标签
不正确的数据:仪表板的图像。
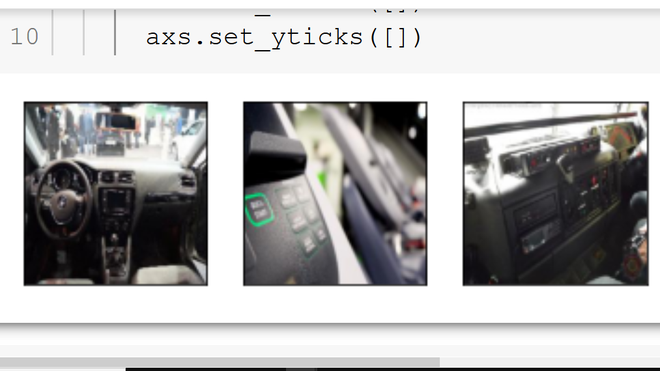
通过删除这些图像,精度变得更加稳定(振荡更少)。需要注意的是,我能够删除这些仪表板图像,因为我在测试数据中没有找到任何类似的图像。
定义 DatasetClass:对于从磁盘加载数据集的模型,pytorch 提供了一个 DatasetClass,我们不需要将整个模型放入内存中。
代码:
Python3
# Creating a VehicleDataset class for loading the images and labels .
# the following class needs to extend from the Dataset class
# provided by pytorch framework and implement the __len__ and __getitem__ methods.
class VehicleDataset(Dataset):
def __init__(self, csv_name, folder, transform = None, label = False):
self.label = label
self.folder = folder
print(csv_name)
self.dataframe = pd.read_csv(self.folder+'/'+csv_name+'.csv')
self.tms = transform
def __len__(self):
return len(self.dataframe)
def __getitem__(self, index):
row = self.dataframe.iloc[index]
imgIndex = row['image_names']
imageFile = self.folder + '/' + img_index
image = Image.open(image_file)
if self.label:
target = row['emergency_or_not']
if target == 0:
encode = torch.FloatTensor([1, 0])
else:
encode = torch.FloatTensor([0, 1])
return self.tms(image), encode
return self.tms(image)
# creating objects of VehicleDataset
# the deep learning models accepts the image to be in tensor format
# this is done using the transforms.ToTensor() methods
transform = transforms.Compose([transforms.ToTensor(),
])
'''
arguments:
csv_name - name of the csv file in out case train.csv
folder - folder in which the images are stored
transform - transforms the image to tensor,
label - used to differentiate between train and test set.
''''
trainDataset = VehicleDataset('train', 'images', label = True, transform = transform)
现在我们已经准备好数据管道,我们需要创建深度学习模型。
CNN模型:
这篇文章假设您对神经网络有一定的了解,因为这超出了本文的范围。我将使用 CNN(卷积神经网络)。该模型有 3 个主要层,分别命名为 conv2d 层、batch Norm 和 max pooling 2d,这里使用的激活函数是 relu:
代码:
Python
# the EmergencyCustomModel class defines our Neural Network
# It inherites from the ImageClassificationBase class which has helper methods
# for printing the loss and accuracy at each epochs.
class EmergencyCustomModel(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Conv2d(3, 32, kernel_size = 3, padding = 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 128, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 2),
# nn.Sigmoid(),
)
def forward(self, xb):
return self.network(xb)
可以在我的github 存储库中的这个笔记本中找到整个模型定义
训练函数:
代码:以下函数用于训练帖子中的所有模型。
Python3
# defining the training method.
# the evaluation method is used to calculate validation accuracy.
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
# The fit method is used to train the model
# parameters
'''
epochs: no. of epochs the model trains
max_lr: maximum learning rate.
train_loader: here we pass the train dataset
val_loader: here we pass the val_dataset
opt_func : The learning algorithm that performs gradient descent.
model : the neural network to train on.
'''
def fit(epochs, max_lr, model, train_loader, val_loader,
weight_decay = 0, grad_clip = None, opt_func = torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up custom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay = weight_decay)
# the loop iterates from 0 to number of epochs.
# the model needs to be set in the train model by calling the model.train.
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
for batch in train_loader:
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
model.epoch_end(epoch, result)
history.append(result)
return history
在开始训练之前,我们需要将数据分成训练集和验证集。这样做是为了使模型可以很好地概括看不见的数据。我们将进行 80 - 20 拆分 80% 训练和 20% 测试。拆分数据后,我们需要将数据集传递给 pytorch 提供的数据加载器。
代码:拆分和创建数据加载器。
Python3
# the batchSize is the number of images passes by the loader at a time.
# reduce this number if theres an out of memory error.
batchSize = 32
valPct = 0.2
# code for splitting the data
# valPct variable is used to split dataset
valSize = int(valPct * len(trainDataset))
trainSize = len(trainDataset) - valSize
trainDs, valDs = random_split(trainDataset, [trainSize, valSize])
# Creating dataloaders.
train_loader = DataLoader(trainDs, batchSize)
val_loader = DataLoader(valDs, batchSize)
现在我们准备通过调用 fit() 方法开始训练。
Python3
customModel = EmergencyCustomModel()
epochs = 10
lr = 0.01
# save the history to visualize later.
history = fit(epochs, lr, customModel, trainDl, valDl)
上述代码的输出:
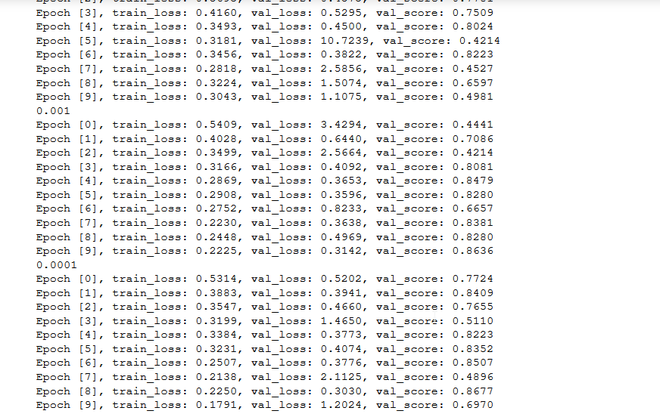
拟合函数的输出
整个代码可在github repo链接中找到,如下所示。
代码:绘图函数用于生成如下所示的损失和准确度图
Python3
'''
parameters:
epochs = number of epochs the model was trained on
hist = the history returned by the fit function.
'''
def plot(hist, epochs = 10):
trainLoss = []
valLoss = []
valScore = []
for i in range(epochs):
trainLoss.append(hist[i]['train_loss'])
valLoss.append(hist[i]['val_loss'])
valScore.append(hist[i]['val_score'])
plt.plot(trainLoss, label ='train_loss')
plt.plot(valLoss, label ='val_loss')
plt.legend()
plt.title('loss')
plt.figure()
plt.plot(valScore, label ='val_score')
plt.legend()
plt.title('accuracy')
# calling the function
plot(history)
输出:绘制损失和准确度图。
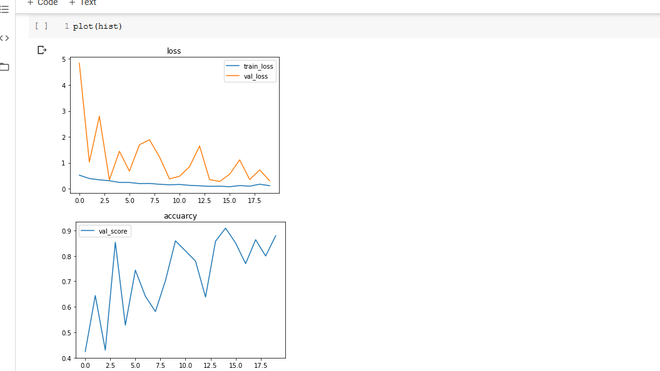
损失和准确度图
过拟合非常少,val_accuracy 在 90% 时达到峰值。再次在这里,我想补充一下,当我在 keras 中创建自定义模型时,我能够实现的高度 val_score 是 83%,改变框架使我们增加了 7%。模式大小的另一件事,使用 pytorch,我能够使用具有超过 3 个 Conv2d 层的模型而不会过度拟合。但是在 keras 中,我只能使用 2 层,而任何更高或更低的层都只会增加训练成本而不会提高准确性。
迁移学习:
使用预训练模型:我使用了两种模型架构 resnet 和densenet。一件事不是densenet模型产生与具有较低时期的resnet模型几乎相似的结果,最重要的是保存的模型占用了一半的内存空间。
代码:
Python3
# to use the pretrained model we make use of the torchvision.models library
class ResNet50(ImageClassificationBase):
def __init__(self):
super().__init__()
# this following line adds the downloads the resnet50 model is it doesn't exits
# and stores it in pretrainedModle
self.pretrainedModel = models.resnet50(pretrained = True)
# since this model was trained on ImageNet data which has 1000 classes but for
# problem we have only 2 so will need to modify the final layer of the model
feature_in = self.pretrainedModel.fc.inFeatures
self.pretrainedModel.fc = nn.Linear(feature_in, 2)
def forward(self, x):
return self.pretrainedModel(x)
# Trainin the model.
# final Learning with
lr = 1e-4
epochs = 5
optFunc = torch.optim.Adam
# Here I have made use of the wd this is used as a regularization parameter
# It helps in preventing overfitting and helps our model to generalize.
bestWd = 1e-4
custom_model = to_device(ResNet50(), device)
hist = fit(epochs, lr, customModel, trainDl, valDl, bestWd, optFunc)
输出:绘制损失和准确度图。

在这里可以看到很多过度拟合,现在 val_score 有所改进。我决定尝试使用循环调度器训练策略,结果如下。我仍然需要用这种方法做更多的实验,但正如大家所见。我已经在一定程度上减少了过度拟合,但 val_accuracy 仍然很低。
使用 Densenet169:密集网络类似于 Resnet,而是添加跳过连接,将其连接起来,因此这些块被称为密集块。
代码:
Python3
class Densenet169(ImageClassificationBase):
def __init__(self):
super().__init__()
# the below statement is used to download and store the pretrained model.
self.pretrained_model = models.densenet169(pretrained = True)
feature_in = self.pretrained_model.classifier.in_features
self.pretrained_model.classifier = nn.Linear(feature_in, 2)
def forward(self, x):
return self.pretrained_model(x)
Training the model
# final Learning with
lr = 1e-4
epochs = 5
optFunc = torch.optim.Adam
bestWd = 1e-4
customModel2 = Densenet169()
hist = fit(epochs, lr, customModel2, trainDl, valDl, bestWd, optFunc)
如果您查看损失和准确度图。过拟合减少了。 val 精度更好,但这是在没有循环调度程序的情况下完成的。
代码:绘制损失和准确度图。

使用提前停止训练可以在 5 个 epoch 处停止。
网络应用程序:
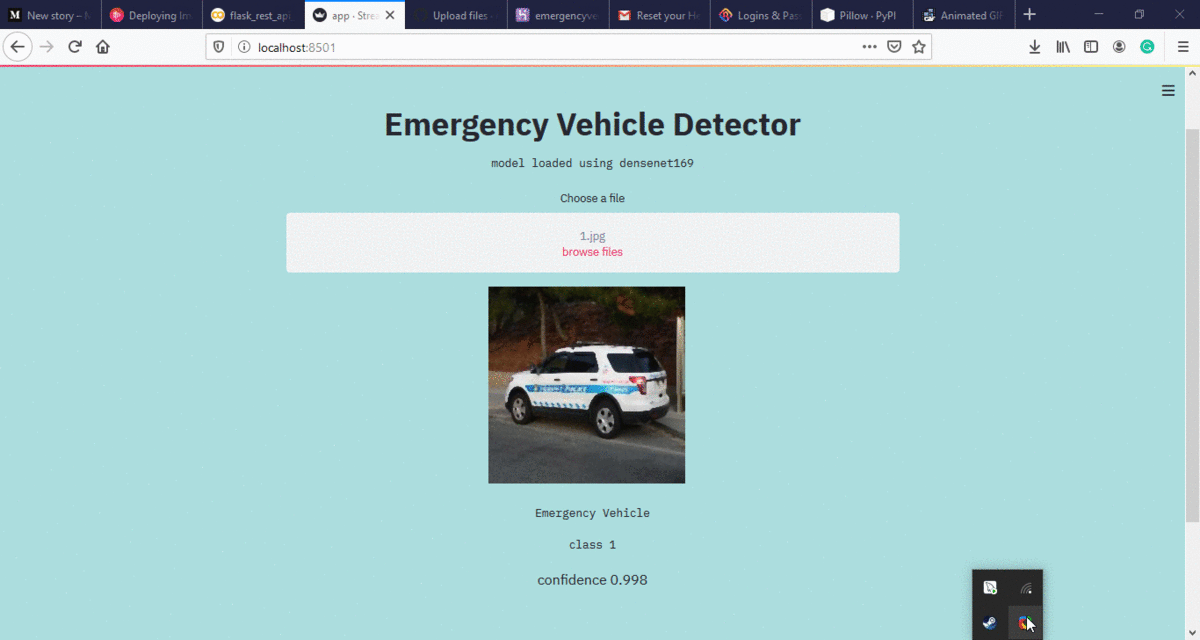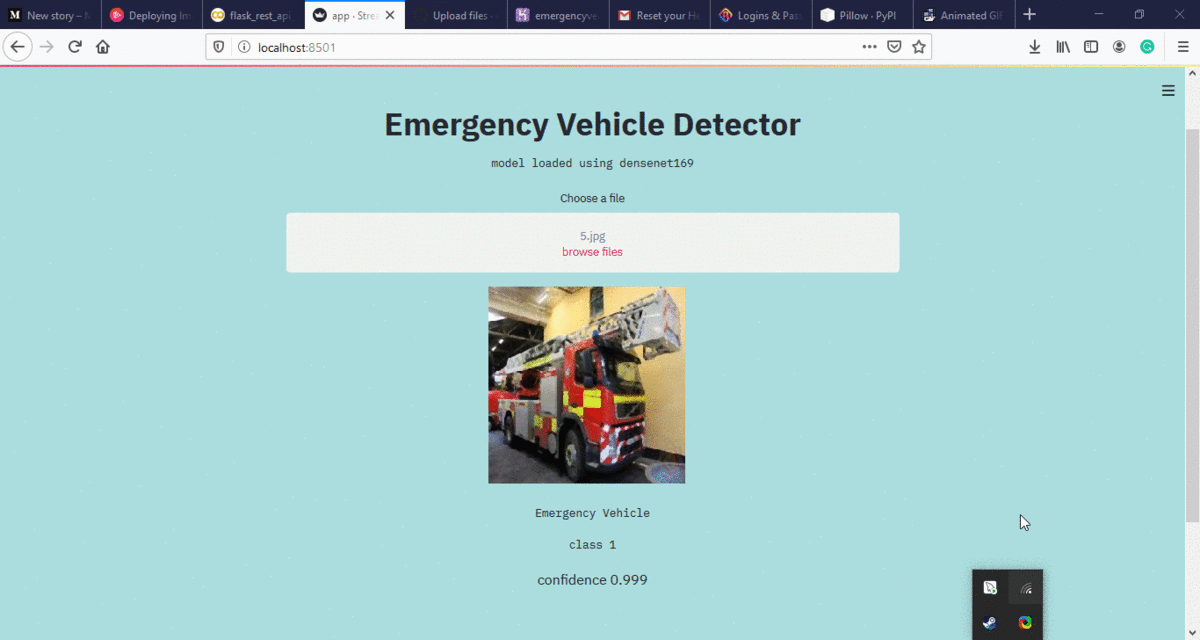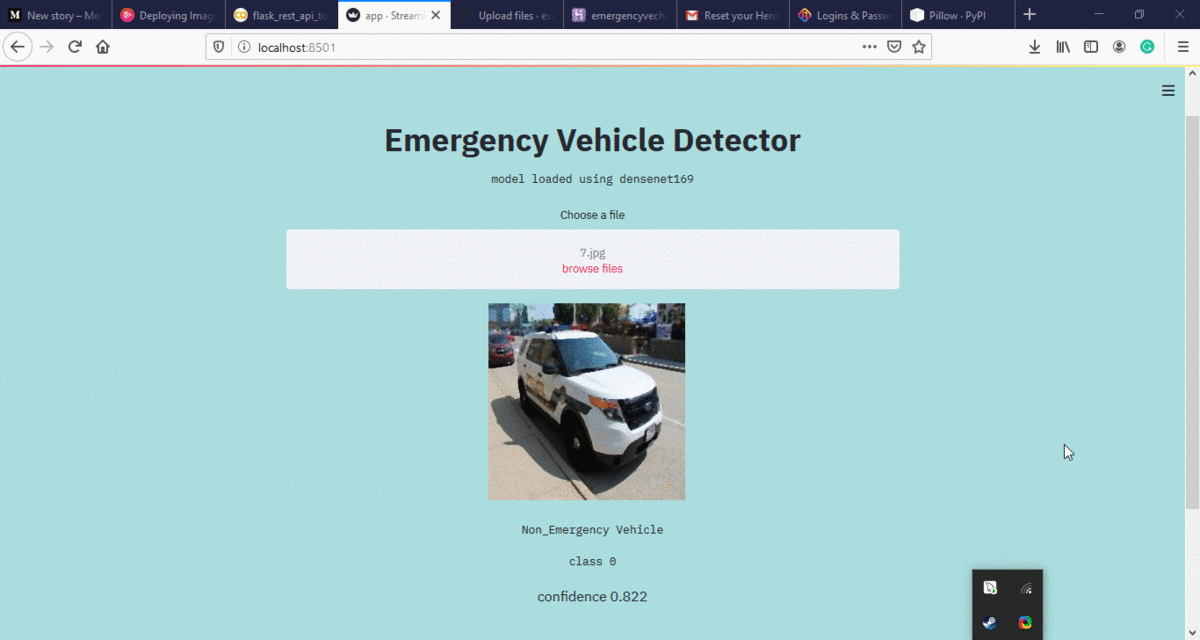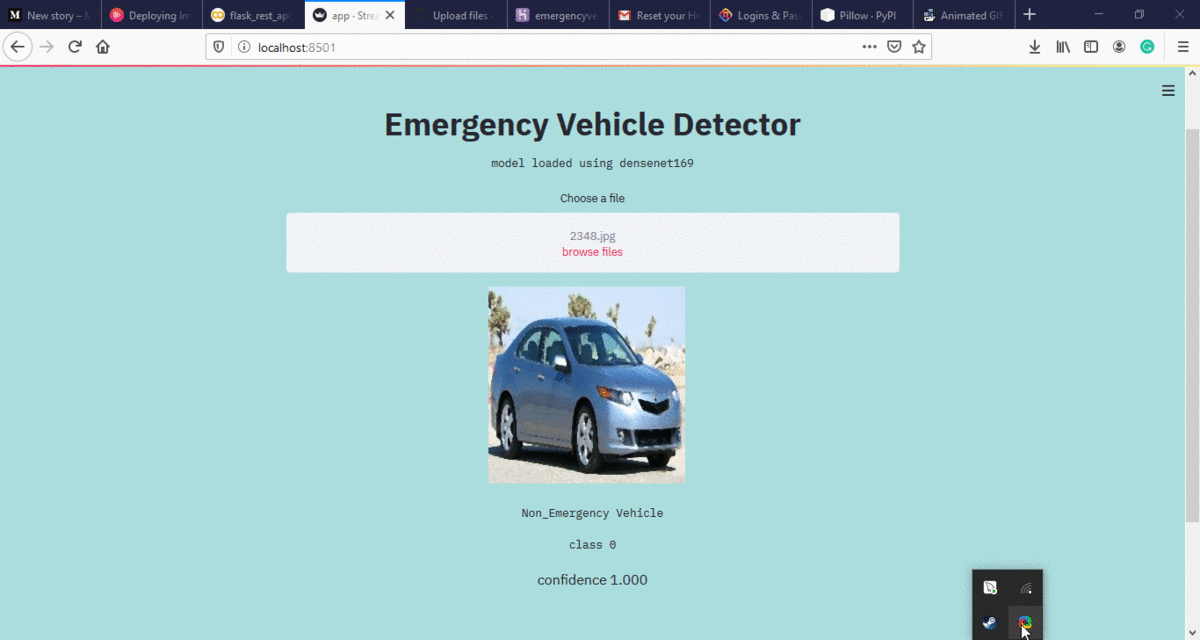
https://emervehicledetector.herokuapp.com/
注意:网络应用程序只接受 jpg 图像。
结论:我能够在 10000 人中获得 200 名,所以我使用上述模型进入了前 2%。所有代码都将在我的 github 存储库中提供:https://github.com/evilc3/EmergencyVehicleDetector
整个笔记本: https://colab.research.google.com/drive/13En-V2A-w2o4uXuDZk0ypktxzX9joXIY?usp=sharing
网络应用链接: https://emervehicledetector.herokuapp.com/