Lasso vs Ridge vs Elastic Net |机器学习
偏见:
偏差是数据为简化目标函数而做出的基本假设。偏差确实帮助我们更好地概括数据,并使模型对单个数据点不那么敏感。它还减少了训练时间,因为目标函数的复杂性降低了高偏差表明对目标函数采取了更多的假设。这有时会导致模型的欠拟合。
高偏差算法的例子包括线性回归、逻辑回归等。
方差:
在机器学习中,方差是一种由于模型对数据集中小波动的敏感性而发生的错误。高方差会导致算法对训练集中的异常值/噪声进行建模。这通常被称为过度拟合。在这种情况下,模型基本上会学习每个数据点,并且在新数据集上进行测试时无法提供良好的预测。
高方差算法的例子包括决策树、KNN 等。

过拟合 vs 欠拟合 vs 恰到好处
线性回归误差:
让我们考虑一个简单的回归模型,该模型旨在根据变量 X 和正态分布误差项的线性组合预测变量 Y 

在哪里
 是在预测中增加一些噪音的正态分布。
是在预测中增加一些噪音的正态分布。这里 是表示我们需要从训练数据中估计的 X 中变量系数的向量。我们需要以产生最低残差的方式来估计它们。此错误定义为:
是表示我们需要从训练数据中估计的 X 中变量系数的向量。我们需要以产生最低残差的方式来估计它们。此错误定义为:

计算
 我们使用以下矩阵变换。
我们使用以下矩阵变换。 
这里的偏差和方差
 可以定义为:
可以定义为: 
和

我们可以根据偏差和方差来简化上面定义的 OLS 方程的误差项,如下所示:

上述等式的第一项表示偏差2 。第二项表示方差,第三项 (
 ) 是不可约误差项。
) 是不可约误差项。 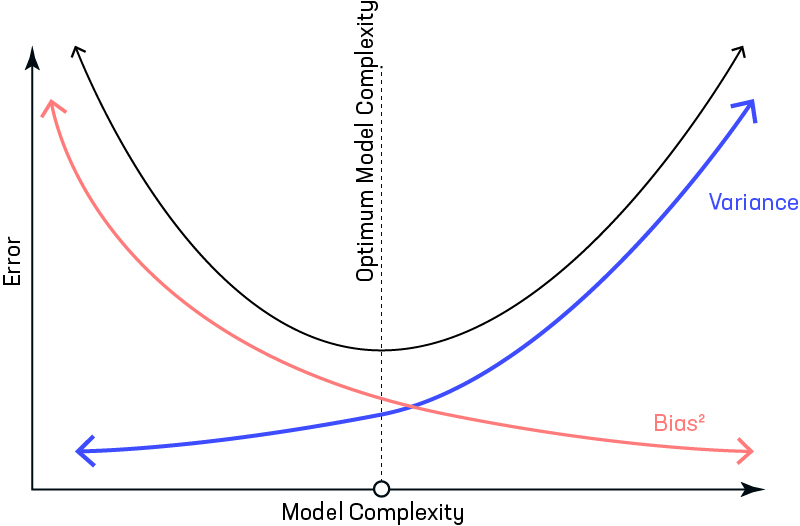
方差/偏差与误差
偏差与方差权衡
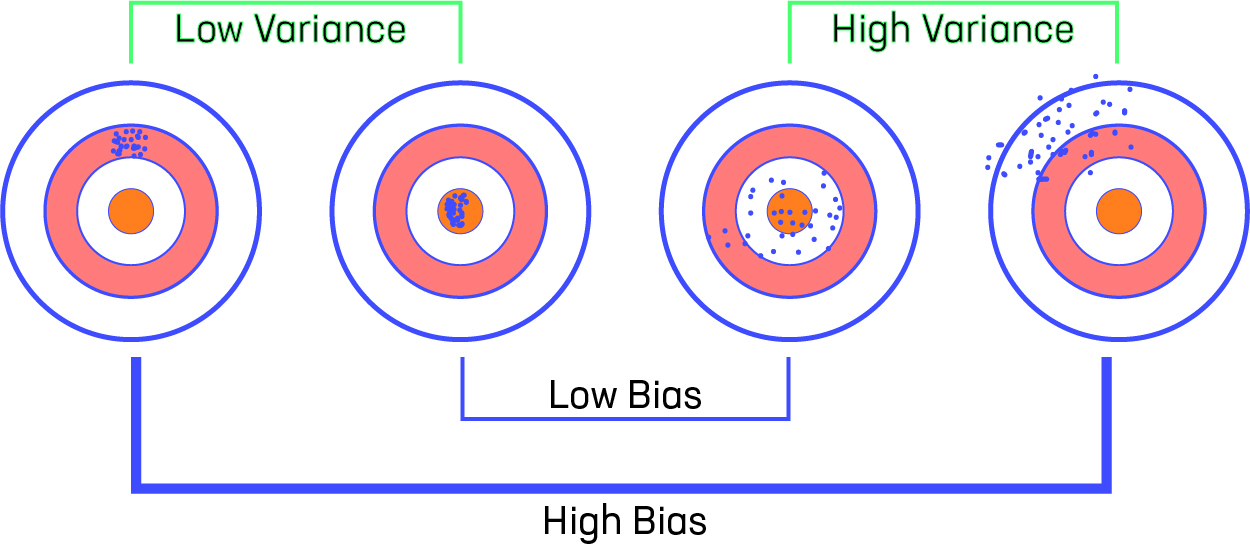
方差-偏差-可视化
让我们考虑一下我们有一个非常准确的模型,这个模型的预测误差很低,而且它不是来自目标(由靶心表示)。该模型具有低偏差和方差。现在,如果预测分散在这里和那里,那么这是高方差的符号,如果预测离目标很远,那么这就是高偏差的符号。
有时我们需要在低方差和低偏差之间做出选择。有一种方法比高方差更喜欢一些偏差,这种方法称为正则化。它适用于大多数分类/回归问题。
岭回归:
在岭回归中,我们添加了一个等于系数平方的惩罚项。 L2项等于系数大小的平方。我们还添加了一个系数 控制那个惩罚期限。在这种情况下,如果
控制那个惩罚期限。在这种情况下,如果 为零,则方程是基本的 OLS 否则,如果
为零,则方程是基本的 OLS 否则,如果 然后它将向系数添加一个约束。当我们增加价值
然后它将向系数添加一个约束。当我们增加价值 此约束导致系数值趋向于零。这会导致低方差(因为某些系数对预测的影响可以忽略不计)和低偏差(系数的最小化降低了预测对特定变量的依赖性)。
此约束导致系数值趋向于零。这会导致低方差(因为某些系数对预测的影响可以忽略不计)和低偏差(系数的最小化降低了预测对特定变量的依赖性)。

在哪里
 是正则化惩罚。
是正则化惩罚。岭回归的局限性:岭回归降低了模型的复杂性,但不会减少变量的数量,因为它永远不会导致系数为零,而只会使其最小化。因此,该模型不利于特征减少。
套索回归:
套索回归代表最小绝对收缩和选择算子。它为成本函数增加了惩罚项。这一项是系数的绝对和。当系数的值从0增加时,该术语会惩罚,导致模型,以减少系数的值以减少损失。岭回归和套索回归之间的区别在于,与从不将系数值设置为绝对零的岭相比,它倾向于使系数绝对为零。

Lasso 回归的局限性:
- Lasso 有时会遇到某些类型的数据。如果预测变量的数量(p)大于观察的数量(n) ,即使所有预测变量都是相关的(或可能在测试集中使用) ,Lasso 也会选择最多 n 个预测变量作为非零。
- 如果有两个或多个高度共线的变量,那么 LASSO 回归随机选择其中一个,这不利于数据的解释
弹性网:
有时,套索回归可能会导致模型中的小偏差,其中预测过于依赖特定变量。在这些情况下,弹性网络被证明更好地结合了 lasso 和 Ridge 的正则化。优点是不容易消除高共线性系数。

参考资料 –弹性网纸