变分自编码器
变分自动编码器是由谷歌和高通公司的 Knigma 和 Welling 于 2013 年提出的。变分自编码器 (VAE) 提供了一种概率方式来描述潜在空间中的观察。因此,与其构建一个输出单个值来描述每个潜在状态属性的编码器,我们将制定我们的编码器来描述每个潜在属性的概率分布。
它有许多应用,如数据压缩、合成数据创建等。
建筑学:
自编码器是一种神经网络,它以无监督的方式从数据集中学习数据编码。它基本上包含两个部分:第一个是编码器,除了最后一层外,与卷积神经网络类似。编码器的目标是从数据集中学习有效的数据编码并将其传递到瓶颈架构中。自编码器的另一部分是解码器,它使用瓶颈层中的潜在空间来重新生成与数据集相似的图像。这些结果以损失函数的形式从神经网络反向传播。
变分自编码器与自编码器的不同之处在于它提供了一种统计方式来描述潜在空间中的数据集样本。因此,在变分自编码器中,编码器在瓶颈层输出概率分布而不是单个输出值。

变分自编码器背后的数学原理:
变分自编码器使用 KL 散度作为其损失函数,其目标是最小化数据集的假设分布和原始分布之间的差异。
假设我们有一个分布 z 并且我们想从中生成观测值 x。换句话说,我们要计算

我们可以通过以下方式做到:

但是,p(x) 的计算可能相当困难

这通常使它成为一个难以处理的分布。因此,我们需要将 p(z|x) 近似为 q(z|x) 以使其成为易于处理的分布。为了更好地将 p(z|x) 逼近 q(z|x),我们将最小化 KL 散度损失,计算两个分布的相似程度:

通过简化,上面的最小化问题等价于下面的最大化问题:

第一项代表重建可能性,另一项确保我们学习到的分布 q 与真实的先验分布 p 相似。
因此,我们的总损失由两项组成,一项是重建误差,另一项是 KL 散度损失:

执行:
在这个实现中,我们将使用 Fashion-MNIST 数据集,这个数据集已经在 keras.datasets API 中可用,所以我们不需要手动添加或上传。
- 首先,我们需要将必要的包导入到我们的Python环境中。我们将使用带有 tensorflow 的 Keras 包作为后端。
代码:
# code
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Layer, Conv2D, Flatten, Dense, Reshape, Conv2DTranspose
import matplotlib.pyplot as plt
- 对于变分自编码器,我们需要定义编码器和解码器两部分的架构,但首先,我们将定义架构的瓶颈层,即采样层。
代码:
# this sampling layer is the bottleneck layer of variational autoencoder,
# it uses the output from two dense layers z_mean and z_log_var as input,
# convert them into normal distribution and pass them to the decoder layer
class Sampling(Layer):
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape =(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
- 现在,我们定义了自动编码器的编码器部分的架构,这部分将图像作为输入并在采样层中对其表示进行编码。
代码:
# Define Encoder Model
latent_dim = 2
encoder_inputs = Input(shape =(28, 28, 1))
x = Conv2D(32, 3, activation ="relu", strides = 2, padding ="same")(encoder_inputs)
x = Conv2D(64, 3, activation ="relu", strides = 2, padding ="same")(x)
x = Flatten()(x)
x = Dense(16, activation ="relu")(x)
z_mean = Dense(latent_dim, name ="z_mean")(x)
z_log_var = Dense(latent_dim, name ="z_log_var")(x)
z = Sampling()([z_mean, z_log_var])
encoder = Model(encoder_inputs, [z_mean, z_log_var, z], name ="encoder")
encoder.summary()
Model: "encoder"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 28, 28, 1)] 0
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 32) 320 input_3[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 64) 18496 conv2d_2[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 3136) 0 conv2d_3[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 16) 50192 flatten_1[0][0]
__________________________________________________________________________________________________
z_mean (Dense) (None, 2) 34 dense_2[0][0]
__________________________________________________________________________________________________
z_log_var (Dense) (None, 2) 34 dense_2[0][0]
__________________________________________________________________________________________________
sampling_1 (Sampling) (None, 2) 0 z_mean[0][0]
z_log_var[0][0]
==================================================================================================
Total params: 69, 076
Trainable params: 69, 076
Non-trainable params: 0
__________________________________________________________________________________________________
- 现在,我们定义自动编码器的解码器部分的架构,这部分以采样层的输出作为输入并输出大小为 (28, 28, 1) 的图像。
代码:
# Define Decoder Architecture
latent_inputs = keras.Input(shape =(latent_dim, ))
x = Dense(7 * 7 * 64, activation ="relu")(latent_inputs)
x = Reshape((7, 7, 64))(x)
x = Conv2DTranspose(64, 3, activation ="relu", strides = 2, padding ="same")(x)
x = Conv2DTranspose(32, 3, activation ="relu", strides = 2, padding ="same")(x)
decoder_outputs = Conv2DTranspose(1, 3, activation ="sigmoid", padding ="same")(x)
decoder = Model(latent_inputs, decoder_outputs, name ="decoder")
decoder.summary()
Model: "decoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 2)] 0
_________________________________________________________________
dense_3 (Dense) (None, 3136) 9408
_________________________________________________________________
reshape_1 (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 14, 14, 64) 36928
_________________________________________________________________
conv2d_transpose_4 (Conv2DTr (None, 28, 28, 32) 18464
_________________________________________________________________
conv2d_transpose_5 (Conv2DTr (None, 28, 28, 1) 289
=================================================================
Total params: 65, 089
Trainable params: 65, 089
Non-trainable params: 0
_________________________________________________________________
- 在这一步中,我们结合模型并使用损失函数定义训练过程。
代码:
# this class takes encoder and decoder models and
# define the complete variational autoencoder architecture
class VAE(keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def train_step(self, data):
if isinstance(data, tuple):
data = data[0]
with tf.GradientTape() as tape:
z_mean, z_log_var, z = encoder(data)
reconstruction = decoder(z)
reconstruction_loss = tf.reduce_mean(
keras.losses.binary_crossentropy(data, reconstruction)
)
reconstruction_loss *= 28 * 28
kl_loss = 1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var)
kl_loss = tf.reduce_mean(kl_loss)
kl_loss *= -0.5
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
return {
"loss": total_loss,
"reconstruction_loss": reconstruction_loss,
"kl_loss": kl_loss,
}
- 现在是训练我们的变分自编码器模型的好时机,我们将训练它 100 个 epoch。但首先我们需要导入时尚 MNIST 数据集。
代码:
# load fashion mnist dataset from keras.dataset API
(x_train, _), (x_test, _) = keras.datasets.fashion_mnist.load_data()
fmnist_images = np.concatenate([x_train, x_test], axis = 0)
# expand dimension to add a color map dimension
fmnist_images = np.expand_dims(fmnist_images, -1).astype("float32") / 255
# compile and train the model
vae = VAE(encoder, decoder)
vae.compile(optimizer ='rmsprop')
vae.fit(fmnist_images, epochs = 100, batch_size = 64)
Epoch 1/100
1094/1094 [==============================] - 7s 6ms/step - loss: 301.9441 - reconstruction_loss: 298.3138 - kl_loss: 3.6303
Epoch 2/100
1094/1094 [==============================] - 7s 6ms/step - loss: 273.5940 - reconstruction_loss: 270.0484 - kl_loss: 3.5456
Epoch 3/100
1094/1094 [==============================] - 7s 6ms/step - loss: 269.3337 - reconstruction_loss: 265.9077 - kl_loss: 3.4260
Epoch 4/100
1094/1094 [==============================] - 7s 6ms/step - loss: 266.8168 - reconstruction_loss: 263.4100 - kl_loss: 3.4068
Epoch 5/100
1094/1094 [==============================] - 7s 6ms/step - loss: 264.9917 - reconstruction_loss: 261.5603 - kl_loss: 3.4314
Epoch 6/100
1094/1094 [==============================] - 7s 6ms/step - loss: 263.5237 - reconstruction_loss: 260.0712 - kl_loss: 3.4525
Epoch 7/100
1094/1094 [==============================] - 7s 6ms/step - loss: 262.3414 - reconstruction_loss: 258.8548 - kl_loss: 3.4865
Epoch 8/100
1094/1094 [==============================] - 7s 6ms/step - loss: 261.4241 - reconstruction_loss: 257.9104 - kl_loss: 3.5137
Epoch 9/100
1094/1094 [==============================] - 7s 6ms/step - loss: 260.6090 - reconstruction_loss: 257.0662 - kl_loss: 3.5428
Epoch 10/100
1094/1094 [==============================] - 7s 6ms/step - loss: 259.9735 - reconstruction_loss: 256.4075 - kl_loss: 3.5660
Epoch 11/100
1094/1094 [==============================] - 7s 6ms/step - loss: 259.4184 - reconstruction_loss: 255.8348 - kl_loss: 3.5836
Epoch 12/100
1094/1094 [==============================] - 7s 6ms/step - loss: 258.9688 - reconstruction_loss: 255.3724 - kl_loss: 3.5964
Epoch 13/100
1094/1094 [==============================] - 7s 6ms/step - loss: 258.5413 - reconstruction_loss: 254.9356 - kl_loss: 3.6057
Epoch 14/100
1094/1094 [==============================] - 7s 6ms/step - loss: 258.2400 - reconstruction_loss: 254.6236 - kl_loss: 3.6163
Epoch 15/100
1094/1094 [==============================] - 7s 6ms/step - loss: 257.9335 - reconstruction_loss: 254.3038 - kl_loss: 3.6298
Epoch 16/100
1094/1094 [==============================] - 7s 6ms/step - loss: 257.6331 - reconstruction_loss: 253.9993 - kl_loss: 3.6339
Epoch 17/100
1094/1094 [==============================] - 7s 6ms/step - loss: 257.4199 - reconstruction_loss: 253.7707 - kl_loss: 3.6492
Epoch 18/100
1094/1094 [==============================] - 6s 6ms/step - loss: 257.1951 - reconstruction_loss: 253.5309 - kl_loss: 3.6643
Epoch 19/100
1094/1094 [==============================] - 7s 6ms/step - loss: 256.9326 - reconstruction_loss: 253.2723 - kl_loss: 3.6604
Epoch 20/100
1094/1094 [==============================] - 7s 6ms/step - loss: 256.7551 - reconstruction_loss: 253.0836 - kl_loss: 3.6715
Epoch 21/100
1094/1094 [==============================] - 7s 6ms/step - loss: 256.5663 - reconstruction_loss: 252.8877 - kl_loss: 3.6786
Epoch 22/100
1094/1094 [==============================] - 7s 6ms/step - loss: 256.4068 - reconstruction_loss: 252.7112 - kl_loss: 3.6956
Epoch 23/100
1094/1094 [==============================] - 7s 6ms/step - loss: 256.2588 - reconstruction_loss: 252.5588 - kl_loss: 3.7000
Epoch 24/100
1094/1094 [==============================] - 7s 6ms/step - loss: 256.0853 - reconstruction_loss: 252.3794 - kl_loss: 3.7059
Epoch 25/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.9321 - reconstruction_loss: 252.2201 - kl_loss: 3.7120
Epoch 26/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.7962 - reconstruction_loss: 252.0814 - kl_loss: 3.7148
Epoch 27/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.6953 - reconstruction_loss: 251.9673 - kl_loss: 3.7280
Epoch 28/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.5534 - reconstruction_loss: 251.8248 - kl_loss: 3.7287
Epoch 29/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.4437 - reconstruction_loss: 251.7134 - kl_loss: 3.7303
Epoch 30/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.3439 - reconstruction_loss: 251.6064 - kl_loss: 3.7375
Epoch 31/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.2326 - reconstruction_loss: 251.5018 - kl_loss: 3.7308
Epoch 32/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.1356 - reconstruction_loss: 251.3933 - kl_loss: 3.7423
Epoch 33/100
1094/1094 [==============================] - 7s 6ms/step - loss: 255.0660 - reconstruction_loss: 251.3224 - kl_loss: 3.7436
Epoch 34/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.9977 - reconstruction_loss: 251.2449 - kl_loss: 3.7528
Epoch 35/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.8857 - reconstruction_loss: 251.1363 - kl_loss: 3.7494
Epoch 36/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.7980 - reconstruction_loss: 251.0481 - kl_loss: 3.7499
Epoch 37/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.7485 - reconstruction_loss: 250.9851 - kl_loss: 3.7634
Epoch 38/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.6701 - reconstruction_loss: 250.9049 - kl_loss: 3.7652
Epoch 39/100
1094/1094 [==============================] - 6s 6ms/step - loss: 254.6105 - reconstruction_loss: 250.8389 - kl_loss: 3.7716
Epoch 40/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.4979 - reconstruction_loss: 250.7333 - kl_loss: 3.7646
Epoch 41/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.4734 - reconstruction_loss: 250.7037 - kl_loss: 3.7697
Epoch 42/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.4408 - reconstruction_loss: 250.6576 - kl_loss: 3.7831
Epoch 43/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.3272 - reconstruction_loss: 250.5562 - kl_loss: 3.7711
Epoch 44/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.3110 - reconstruction_loss: 250.5354 - kl_loss: 3.7755
Epoch 45/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.1982 - reconstruction_loss: 250.4256 - kl_loss: 3.7726
Epoch 46/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.1655 - reconstruction_loss: 250.3795 - kl_loss: 3.7860
Epoch 47/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.0979 - reconstruction_loss: 250.3105 - kl_loss: 3.7875
Epoch 48/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.0801 - reconstruction_loss: 250.2973 - kl_loss: 3.7828
Epoch 49/100
1094/1094 [==============================] - 7s 6ms/step - loss: 254.0101 - reconstruction_loss: 250.2270 - kl_loss: 3.7831
Epoch 50/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.9512 - reconstruction_loss: 250.1681 - kl_loss: 3.7831
Epoch 51/100
1094/1094 [==============================] - 7s 7ms/step - loss: 253.9307 - reconstruction_loss: 250.1408 - kl_loss: 3.7899
Epoch 52/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.8858 - reconstruction_loss: 250.1059 - kl_loss: 3.7800
Epoch 53/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.8118 - reconstruction_loss: 250.0236 - kl_loss: 3.7882
Epoch 54/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.8171 - reconstruction_loss: 250.0325 - kl_loss: 3.7845
Epoch 55/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.7622 - reconstruction_loss: 249.9735 - kl_loss: 3.7887
Epoch 56/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.7338 - reconstruction_loss: 249.9380 - kl_loss: 3.7959
Epoch 57/100
1094/1094 [==============================] - 6s 6ms/step - loss: 253.6761 - reconstruction_loss: 249.8792 - kl_loss: 3.7969
Epoch 58/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.6236 - reconstruction_loss: 249.8283 - kl_loss: 3.7954
Epoch 59/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.6181 - reconstruction_loss: 249.8236 - kl_loss: 3.7945
Epoch 60/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.5509 - reconstruction_loss: 249.7587 - kl_loss: 3.7921
Epoch 61/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.5124 - reconstruction_loss: 249.7126 - kl_loss: 3.7998
Epoch 62/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.4739 - reconstruction_loss: 249.6683 - kl_loss: 3.8056
Epoch 63/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.4609 - reconstruction_loss: 249.6567 - kl_loss: 3.8042
Epoch 64/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.4066 - reconstruction_loss: 249.6020 - kl_loss: 3.8045
Epoch 65/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.3578 - reconstruction_loss: 249.5580 - kl_loss: 3.7998
Epoch 66/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.3728 - reconstruction_loss: 249.5609 - kl_loss: 3.8118
Epoch 67/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.3523 - reconstruction_loss: 249.5351 - kl_loss: 3.8171
Epoch 68/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.2646 - reconstruction_loss: 249.4452 - kl_loss: 3.8194
Epoch 69/100
1094/1094 [==============================] - 6s 6ms/step - loss: 253.2642 - reconstruction_loss: 249.4603 - kl_loss: 3.8040
Epoch 70/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.2227 - reconstruction_loss: 249.4159 - kl_loss: 3.8068
Epoch 71/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.1848 - reconstruction_loss: 249.3755 - kl_loss: 3.8094
Epoch 72/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.1812 - reconstruction_loss: 249.3737 - kl_loss: 3.8074
Epoch 73/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.1803 - reconstruction_loss: 249.3743 - kl_loss: 3.8059
Epoch 74/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.1295 - reconstruction_loss: 249.3114 - kl_loss: 3.8181
Epoch 75/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.0516 - reconstruction_loss: 249.2391 - kl_loss: 3.8125
Epoch 76/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.0736 - reconstruction_loss: 249.2582 - kl_loss: 3.8154
Epoch 77/100
1094/1094 [==============================] - 6s 6ms/step - loss: 253.0331 - reconstruction_loss: 249.2200 - kl_loss: 3.8131
Epoch 78/100
1094/1094 [==============================] - 7s 6ms/step - loss: 253.0479 - reconstruction_loss: 249.2272 - kl_loss: 3.8207
Epoch 79/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.9317 - reconstruction_loss: 249.1137 - kl_loss: 3.8179
Epoch 80/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.9578 - reconstruction_loss: 249.1483 - kl_loss: 3.8095
Epoch 81/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.9072 - reconstruction_loss: 249.0963 - kl_loss: 3.8109
Epoch 82/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.8793 - reconstruction_loss: 249.0646 - kl_loss: 3.8147
Epoch 83/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.8914 - reconstruction_loss: 249.0676 - kl_loss: 3.8238
Epoch 84/100
1094/1094 [==============================] - 6s 6ms/step - loss: 252.8365 - reconstruction_loss: 249.0121 - kl_loss: 3.8244
Epoch 85/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.8063 - reconstruction_loss: 248.9844 - kl_loss: 3.8218
Epoch 86/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.7960 - reconstruction_loss: 248.9777 - kl_loss: 3.8183
Epoch 87/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.7733 - reconstruction_loss: 248.9529 - kl_loss: 3.8204
Epoch 88/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.7303 - reconstruction_loss: 248.9055 - kl_loss: 3.8248
Epoch 89/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.7225 - reconstruction_loss: 248.8902 - kl_loss: 3.8323
Epoch 90/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.6822 - reconstruction_loss: 248.8549 - kl_loss: 3.8273
Epoch 91/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.6540 - reconstruction_loss: 248.8314 - kl_loss: 3.8227
Epoch 92/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.6540 - reconstruction_loss: 248.8239 - kl_loss: 3.8300
Epoch 93/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.6213 - reconstruction_loss: 248.7778 - kl_loss: 3.8435
Epoch 94/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.5990 - reconstruction_loss: 248.7594 - kl_loss: 3.8397
Epoch 95/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.5786 - reconstruction_loss: 248.7413 - kl_loss: 3.8373
Epoch 96/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.5839 - reconstruction_loss: 248.7411 - kl_loss: 3.8427
Epoch 97/100
1094/1094 [==============================] - 7s 7ms/step - loss: 252.5364 - reconstruction_loss: 248.6960 - kl_loss: 3.8404
Epoch 98/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.5347 - reconstruction_loss: 248.6915 - kl_loss: 3.8431
Epoch 99/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.4996 - reconstruction_loss: 248.6569 - kl_loss: 3.8428
Epoch 100/100
1094/1094 [==============================] - 7s 6ms/step - loss: 252.4938 - reconstruction_loss: 248.6405 - kl_loss: 3.8533
- 在这一步中,我们显示训练结果,我们将根据它们在潜在空间向量中的值来显示这些结果。
代码:
def plot_latent(encoder, decoder):
# display a n * n 2D manifold of imagess
n = 10
img_dim = 28
scale = 2.0
figsize = 15
figure = np.zeros((img_dim * n, img_dim * n))
# linearly spaced coordinates corresponding to the 2D plot
# of images classes in the latent space
grid_x = np.linspace(-scale, scale, n)
grid_y = np.linspace(-scale, scale, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = decoder.predict(z_sample)
images = x_decoded[0].reshape(img_dim, img_dim)
figure[
i * img_dim : (i + 1) * img_dim,
j * img_dim : (j + 1) * img_dim,
] = images
plt.figure(figsize =(figsize, figsize))
start_range = img_dim // 2
end_range = n * img_dim + start_range + 1
pixel_range = np.arange(start_range, end_range, img_dim)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap ="Greys_r")
plt.show()
plot_latent(encoder, decoder)

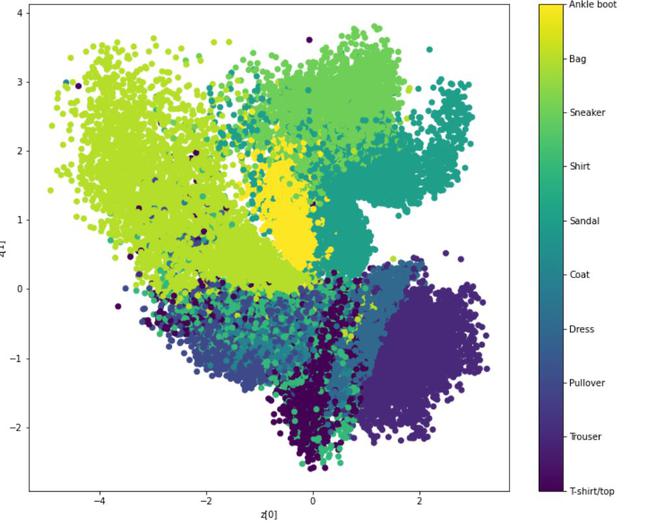
- 为了更清楚地了解我们的代表性潜在向量值,我们将根据编码器生成的相应潜在维度的值绘制训练数据的散点图。
代码:
def plot_label_clusters(encoder, decoder, data, test_lab):
z_mean, _, _ = encoder.predict(data)
plt.figure(figsize =(12, 10))
sc = plt.scatter(z_mean[:, 0], z_mean[:, 1], c = test_lab)
cbar = plt.colorbar(sc, ticks = range(10))
cbar.ax.set_yticklabels([labels.get(i) for i in range(10)])
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.show()
labels = {0 :"T-shirt / top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot"}
(x_train, y_train), _ = keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1).astype("float32") / 255
plot_label_clusters(encoder, decoder, x_train, y_train)
参考:
- 变分自编码器论文
- Keras 变分自动编码器