Beta 变分自动编码器中的解缠结
Beta Variational Autoencoders 由 Deepmind 的研究人员于 2017 年提出。它在 2017 年国际学习表示会议 (ICLR) 上被接受。在学习 Beta-variational autoencoder 之前,请查看这篇关于变分自动编码器的文章。
如果在变分自编码器中,如果每个变量只对数据集的一个特征/属性敏感,而对另一个属性相对不变,则称为数据集的解纠缠表示。具有解开表示的优点是模型易于泛化并具有良好的可解释性。这是 beta 变分自动编码器的主要目标,即实现解缠结。例如,对人脸进行训练以确定该人的性别的神经网络需要在不同的维度上捕获人脸的不同特征(如脸宽、头发颜色、眼睛颜色),以确保解开纠缠。
B-VAE 将参数 B 添加到变分自动编码器,作为节点的平衡 b/w 潜在容量和具有重建精度的独立约束。添加这个超参数背后的动机是最大化生成真实数据集的概率,同时最小化真实数据到估计数据的概率很小,如下 .
.
为了写出下面的等式,我们需要使用库恩-塔克条件。
其中 KKT 乘数是正则化系数,它限制潜在通道 z 的容量,并由于高斯先验p(z)的各向同性性质而对学习后验施加隐式独立压力。
现在,我们使用上述互补松弛假设再次编写此代码以获得 Beta-VAE 公式:
Beta-VAE 尝试通过使用超参数β > 1优化先验分布和近似分布之间的严重惩罚 KL 散度,通过条件独立的数据生成因子来学习解开的表示。
![max_{\phi,\theta}E_{x \propto D}\left [ E_{z \sim q_{\phi}(z|x)} log p_{\theta} (x|z) \right ] \\ subject \, to \, D_{Kl}(q_{\phi}(z|x) || p_{\theta} (z) ) < \delta](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Disentanglement_in_Beta_Variational_Autoencoders_4.png "由 QuickLaTeX.com 渲染")
我们可以在 kkT 条件下用拉格朗日乘数 Beta 重写上述方程。上式等于以下优化条件:
建筑学:
与变分自动编码器相比,Beta 变分自动编码器具有相似的架构(参数 beta 除外)。完整的设置包含两个网络编码器和解码器。编码器将图像作为输入并生成潜在表示,而解码器将输入该潜在表示并尝试重建图像。在这里,潜在表示由包含两个变量(均值和方差)的正态分布表示。但是解码器只需要一种潜在表示。这是通过从正态分布中抽样来完成的。
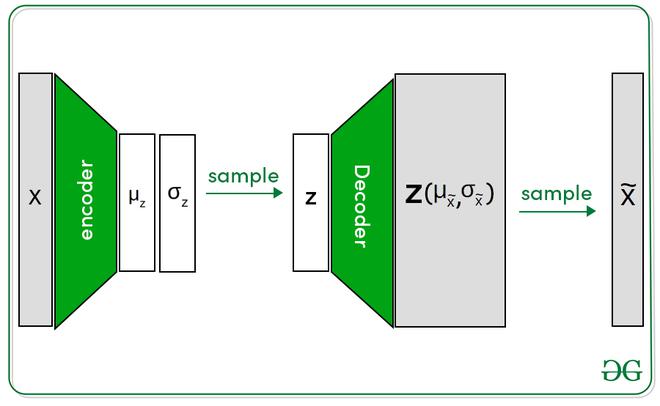
Beta-VAE 架构
B-VAE 中的解缠结:
B-VAE 与 InfoGAIN 原理密切相关,即可以存储的最大信息为:
其中, I是互信息,beta 是拉格朗日乘数,这里这个函数的目标是最大化潜在信息 b/w 潜在瓶颈 Z 和任务 Y,同时丢弃所有可能存在于输入中的与 Y 无关的信息。
作者通过将后验分布q(z|x)作为重建任务的信息瓶颈来对该架构进行实验。他们得出结论,后验分布通过最小化 β 加权 KL 项和最大化数据对数似然来有效地传输有关数据点x的信息。
在这个 VAE 中,鼓励后验分布匹配单位高斯先验(正态分布)。由于后验和先验被分解,后验可以使用重新参数化技巧来计算,我们可以从信息论的角度将q(z|x)视为一组独立的加性高斯白噪声通道z i ,每个通道都有噪声传输有关数据输入x n的信息。
现在,β-VAE 目标的 KL 散度项是每个数据样本可以通过潜在通道传输的信息量的上限。 KL散度为零时
q(zi |x) = p(z) ,即μ i始终为零, σ i始终为 1,这意味着潜在通道z i的容量为零。
因此,潜在通道的容量只能通过在数据点上分散后验均值或减小后验方差来增加,这两者都会增加 KL 散度项。