DeepPose:通过深度神经网络估计人体姿势
DeepPose 是谷歌的研究人员在 2014 年计算机视觉和模式识别会议上为姿态估计提出的。他们致力于将姿势估计问题制定为针对身体关节的基于 DNN 的回归问题。他们提出了一系列 DNN 回归器,导致高精度姿态估计。
建筑学:
姿势向量:
- 为了以姿势的形式表达人体,本文作者将所有k 个身体部位的位置编码为称为姿势向量的关节,定义如下
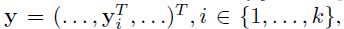
- 其中 y i表示第 i个身体关节位置的 x, y 坐标。
- 图像以(x, y)的形式表示,其中 x 是图像数据,y 是地面真实姿势向量的数据。
- 因为,这里描述的坐标是完整图像大小的绝对图像坐标。如果我们调整可能导致问题的图像大小。因此,我们标准化了坐标 wrt 一个边界框 b,它限制了人体或其某些部分。这些框由b = (b c , b h , b w, ) 表示,其中 b c是边界框的中心,b h是边界的高度,b w是边界的宽度。
- 我们使用以下公式对位置坐标进行了标准化。

- 最后我们得到归一化的姿势向量坐标。

CNN架构

- 这篇论文的作者使用 AlexNet 作为他们的 CNN 架构,因为它在图像定位任务上表现出了很好的结果。

- 其中 theta 表示可训练参数(权重和偏差),shi 表示应用于归一化姿态向量N(x)的神经架构,预测输出 y *可以通过输出 (N -1 ) 的去归一化获得。
- 该神经网络架构采用220×220大小的图像并应用4步长。
- CNN 架构包含 7 层,可以列出为: C(55×55×96) — LRN — P — C(27×27×256) — LRN — P — C(13×13×384) — C(13 ×13×384) — C(13×13×256) — P — F(4096) — F(4096)
- 其中C是卷积层,它使用 ReLU 作为激活函数在模型中引入非线性, LRN是局部响应归一化, P是池化层, F是全连接层。
- 最后一层架构输出2k个关节坐标。
- 参数总数为4000万。
- 该架构使用 L2 损失函数来最小化预测坐标和地面实况损失函数之间的距离。

- 其中k是图像中的关节数
DNN 回归器:
- 增加输入大小以获得更精细的姿态估计并不容易,因为这会增加已经大量的参数。因此,提出了一系列姿势回归器来改进姿势估计。
- 现在,我们用以下等式表示第一阶段
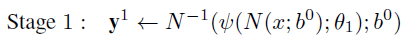
- 其中 b 0表示由人体检测器获得的完整图像或边界框。
- 现在对于后续阶段 s>= 2:
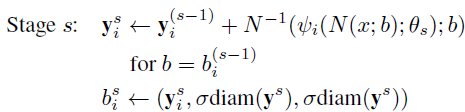
- 其中, diam( y )是相对关节的距离,例如左肩和右臀部,然后按 ?要做到吗?直径( y )。
- DNN 回归器的级联提高了准确性,我们可以从以下图像中注意到。

指标:
- Percentage of Correct Parts (PCP) :测量肢体的检测率,如果两个预测关节位置与真实肢体关节位置之间的距离最多为肢体长度的一半,则认为检测到肢体。然而,它有一些缺点,比如惩罚较短和难以检测的肢体。
- Percent of Detected Joints (PDJ) :为了解决上述方法造成的缺陷,基于关节检测提出了另一种度量如果预测关节和真实关节之间的距离在躯干的某个部分内,则认为检测到关节直径。通过改变这个分数,可以获得不同程度的定位精度的检测率。
结果:
- Framed Label In Cinema (FLIC) 数据集:该数据集包含 4000 个训练图像和 1000 个来自好莱坞电影的不同姿势和服装的测试图像。对于每个标记的人,标记了 10 个上半身关节。


- Leeds Sports Dataset (LSP):该数据集包含来自体育活动的 11000 个训练图像和 1000 个测试图像,这些图像在外观尤其是关节方面具有挑战性。在这个数据集中,每个人的全身都标有 14 个关节。

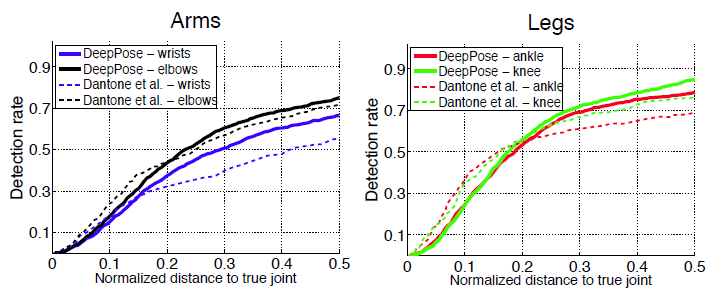

- 为了解决在 FLIC 和 LSP 数据集上训练的模型的泛化问题,还在 Buffy 数据集和 Image Parse 数据集上评估了性能。


参考:
- 深姿势纸