OpenPose:人体姿势估计方法
OpenPose 是第一个在单张图像上联合检测人体、手、面部和足部关键点(共 135 个关键点)的实时多人系统。它是由卡内基梅隆大学的研究人员提出的。它们以Python代码、C++ 实现和 Unity 插件的形式发布。这些资源可以从 OpenPose 存储库下载。
建筑学:
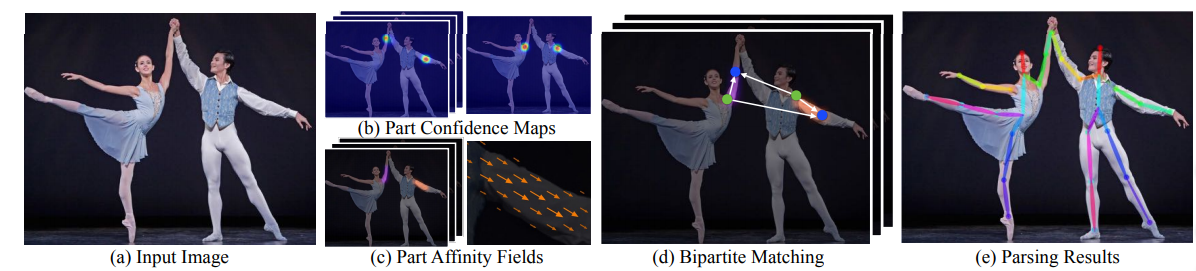
- 在第一步中,图像通过基线 CNN 网络以提取论文中输入的特征图。在本文中,三位作者使用了 VGG-19 网络的前 10 层。
- 然后在多级 CNN 管道中处理特征图以生成部件置信度图和部件亲和性字段
- 零件置信度图:
- 零件相似性字段
- 在最后一步中,上面生成的Confidence Maps和Part Affinity Fields通过贪心二部匹配算法进行处理,以获得图像中每个人的姿势。
置信图和部件亲和性字段
- 置信度图:置信度图是对特定身体部位可以位于任何给定像素中的信念的 2D 表示。置信图由以下等式描述:

其中J是身体部位位置的数量。

多阶段CNN:
上述多CNN架构主要分为三个步骤:

- 第一组阶段预测部分亲和字段从基础网络 F 的特征图中提炼 L t 。
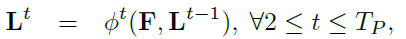
- 第二组阶段使用来自前几层的输出 Part Affinity Fields 来细化置信图检测的预测。
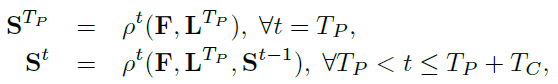
- 然后将最终的 S(置信度图)和 L(部分亲和域)传递给贪婪算法以进行进一步处理。
损失函数:
L2 损失函数用于计算预测置信度图和部分亲和性字段与地面实况图和字段之间的损失。
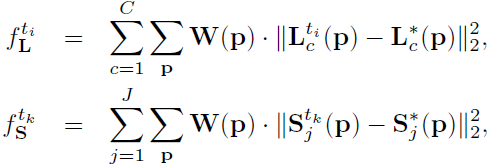
其中L c *是真值部分亲和域, S j *是真值部分置信度图, W是一个二进制掩码,当像素 p 处缺少注释时, W ( p ) = 0。这是为了防止这些掩码可能产生的额外损失。每个阶段的中间监督用于通过定期补充梯度来解决梯度消失问题。

信心地图:
每个人 k 和每个身体部位 j 的置信度图定义为:
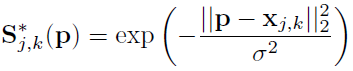
它是一条渐变的高斯曲线,其中sigma控制峰值的传播。网络的预测峰值是由最大运算符对单个置信度图的聚合。
零件相似性字段:
部分亲和力字段是必需的,特别是在多人姿势检测中,我们需要将正确的身体部位映射到其身体。因为对于多人来说,有多个头、手、肩膀等。因此,当它们紧密地组合在一起时,有时会变得难以区分。 PAF 提供了属于同一个人的身体不同部位之间的联系。身体部位之间更强的 PAF 联系表示这些身体部位属于同一个人的可能性很高。

- 如果 p 在肢体上,则L*是单位向量,否则为 0。
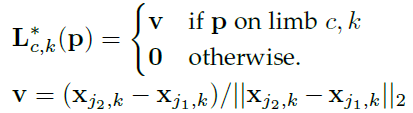
- 沿线段预测的 Part 亲和性字段 L c用于测量两个候选部分位置 dj 1和 dj 2的置信度:
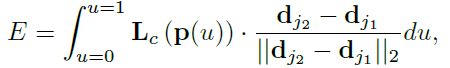
- 对于多人,总 E 需要最大化:
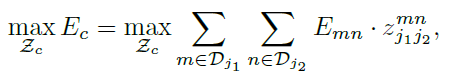
- 有多种方法可以连接身体部位,如下图所示:
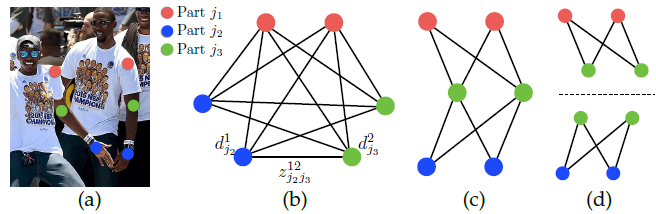
- 通过身体部位检测进行关联。
- 通过考虑所有边进行关联并生成 k 部分图
- 通过生成树结构关联。
- 通过使用贪婪算法生成不同的二部图进行关联。
来自 CMUPose 的变化:
CMUPose 是 OpenPose 的早期版本。正是该架构赢得了 COCO 2016 2016 年关键点检测挑战赛。
- 在用于细化置信度图和 Part Affinity 的多 CNN 架构中,内核 7 的卷积被替换为内核大小为 3 的 3 个卷积,这些卷积在末尾连接。这导致操作次数从 97 次减少到 51 次。卷积的串联允许网络字段同时保留更高级别和更低级别的特征。
- 作者还得出结论,部分亲和场 (PAF) 细化比置信图更重要,即使没有置信图也能带来更高的准确度。因此,多 CNN 架构首先优化 PAF,然后再优化置信度图。
足部检测:

OpenPose 还提出了一种足部检测算法。它使 OpenPose 成为 第一个组合的身体和足部关键点数据集和检测器。通过添加它能够更准确地检测脚踝。

车辆检测:

与body Pose detection类似,OpenPose的作者在Vehicle Detection上对该算法进行了实验。它记录了高平均精度和召回率。

结果:
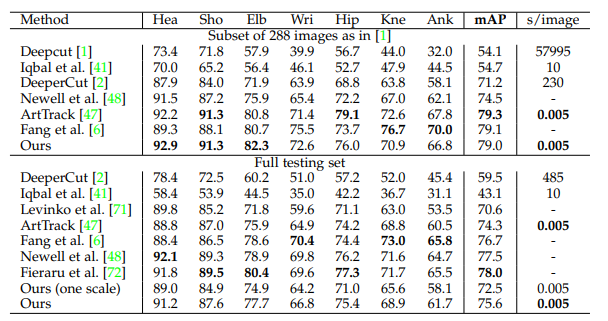
- 在 MPII Multi-Person 数据集中,OpenPose 获得了最先进的 mAP或 288 个图像子集以及完整的测试集。
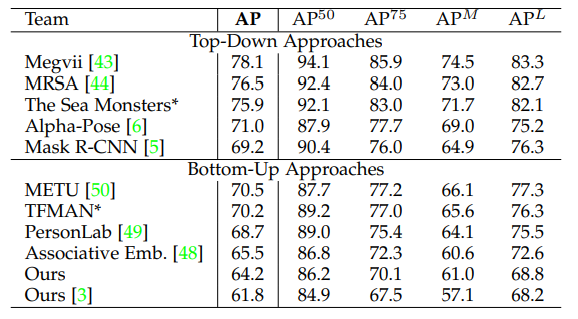
- 在 COCO 关键点挑战中,有两种方法。自顶向下的方法首先检测人物然后检测关键点,而自底向上的方法是首先检测关键点以形成人物骨架。这是因为当只考虑更高比例的人时,准确率会下降更多。
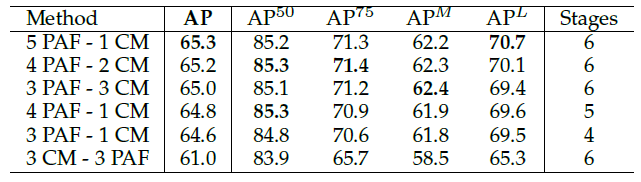
- 下表记录了使用不同数量的 PAF 和 CM 时 COCO 关键点数据集的平均精度。从上表可以得出的结论是,增加 PAF 可以增加平均精度和平均召回率,但对于置信图则不然。
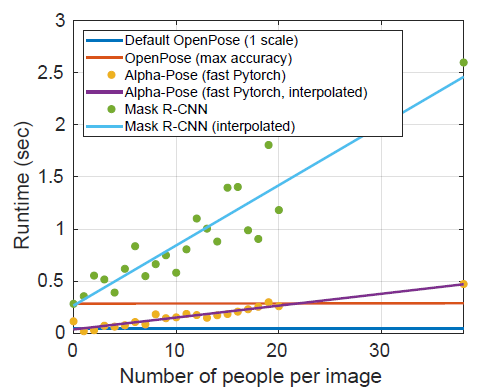
- 下图显示,与 Mask-RCNN、AlphaPose 等自上而下的方法不同,OpenPose 对图像中出现的人数几乎没有影响。
注意事项:

- 当真实示例具有非典型姿势和倒置示例时,OpenPose 在估计姿势时会遇到问题。
- 在人员重叠的高度拥挤的图像中,该方法倾向于合并来自不同人的注释,而忽略其他人,因为重叠的 PAF 使贪婪的多人解析失败
参考:
- OpenPose 姿势估计纸
- OpenPose Github 存储库