XGBoost
XgBoost 代表 Extreme Gradient Boosting,由华盛顿大学的研究人员提出。它是一个用 C++ 编写的库,可优化梯度提升的训练。
在了解 XGBoost 之前,我们首先需要了解树,尤其是决策树:
决策树:
决策树是一种类似流程图的树结构,其中每个内部节点表示对属性的测试,每个分支表示测试的结果,每个叶节点(终端节点)持有一个类标签。
可以通过基于属性值测试将源集拆分为子集来“学习”树。这个过程以递归方式在每个派生的子集上重复,称为 递归分区。当节点处的子集都具有相同的目标变量值时,或者当拆分不再为预测增加值时,递归完成。
装袋:
Bagging 分类器是一个集成元估计器,它将每个基分类器拟合到原始数据集的随机子集上,然后聚合它们各自的预测(通过投票或平均)以形成最终预测。这种元估计器通常可以用作减少黑盒估计器(例如,决策树)方差的一种方式,方法是将随机化引入其构建过程,然后对其进行集成。
每个基分类器与一个训练集并行训练,该训练集是通过从原始训练数据集中随机抽取、替换的 N 个示例(或数据)生成的,其中 N 是原始训练集的大小。每个基分类器的训练集彼此独立。许多原始数据可能会在生成的训练集中重复,而其他数据可能会被遗漏。
Bagging 通过平均或投票来减少过拟合(方差),然而,这会导致偏差的增加,但可以通过方差的减少来补偿。
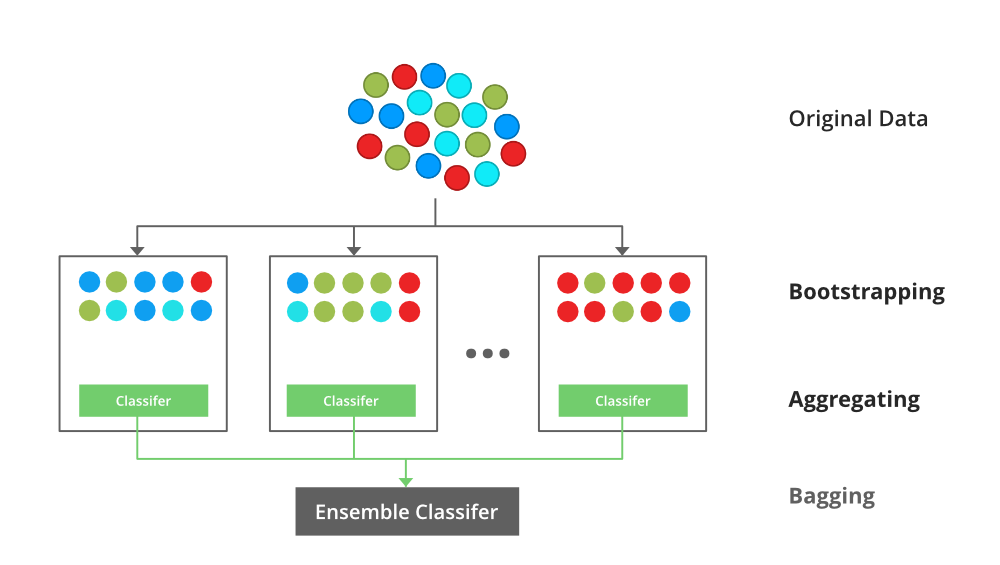
装袋分类器
随机森林:
每棵决策树都有高方差,但是当我们将它们并行组合在一起时,结果方差很低,因为每棵决策树都在该特定样本数据上得到了完美的训练,因此输出不依赖于一个决策树,而是多个决策树木。在分类问题的情况下,使用多数投票分类器获取最终输出。在回归问题的情况下,最终输出是所有输出的平均值。这部分是聚合。
这背后的基本思想是结合多个决策树来确定最终输出,而不是依赖于单个决策树。
随机森林有多个决策树作为基础学习模型。我们从数据集中随机执行行采样和特征采样,形成每个模型的样本数据集。这部分称为引导程序。
提升:
Boosting 是一种集成建模技术,它试图从弱分类器的数量中构建一个强分类器。它是通过串联使用弱模型来构建模型来完成的。首先,根据训练数据建立模型。然后建立第二个模型,它试图纠正第一个模型中存在的错误。继续此过程并添加模型,直到正确预测完整的训练数据集或添加最大数量的模型。
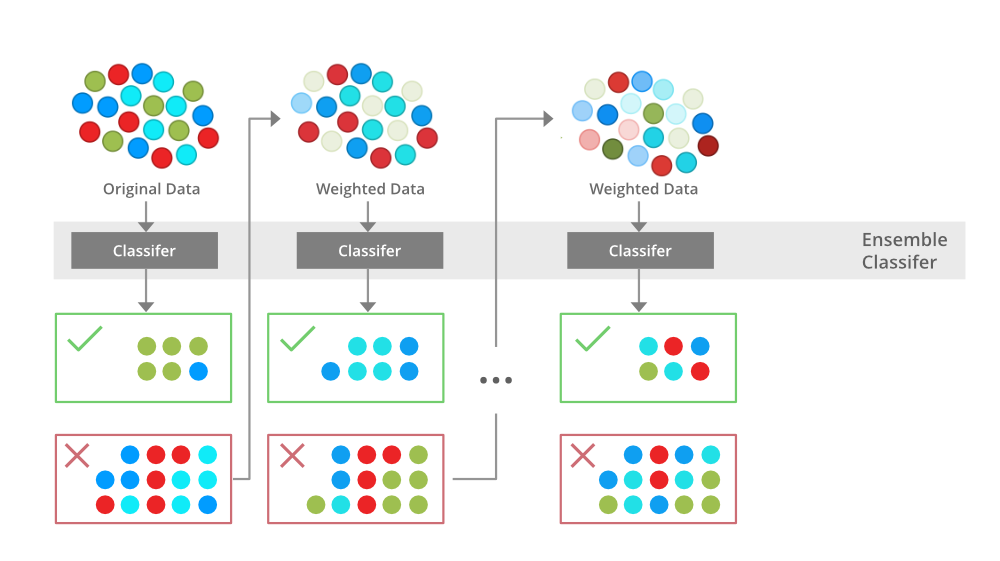
提升
梯度提升
梯度提升是一种流行的提升算法。在梯度提升中,每个预测器都会纠正其前任的错误。与 Adaboost 相比,训练实例的权重没有调整,而是使用前任的残差作为标签来训练每个预测器。
有一种称为梯度提升树的技术,其基础学习器是 CART(分类和回归树)。
XGBoost
XGBoost 是梯度提升决策树的一种实现。 XGBoost 模型主要在许多 Kaggle 比赛中占据主导地位。
在该算法中,决策树是按顺序创建的。权重在 XGBoost 中起着重要作用。将权重分配给所有自变量,然后将其馈入预测结果的决策树。树预测错误的变量的权重增加,然后将这些变量馈送到第二个决策树。然后将这些单独的分类器/预测器组合起来以提供强大且更精确的模型。它可以处理回归、分类、排名和用户定义的预测问题。
XgBoost 背后的数学
在开始讨论有关梯度提升的数学之前,这里有一个简单的 CART 示例,用于分类某人是否会喜欢假设的计算机游戏 X。树的示例如下:
然后将每个单独的决策树的预测分数相加得到如果你看这个例子,一个重要的事实是两棵树试图相互补充。在数学上,我们可以将我们的模型写成以下形式

其中,K 是树的数量,f 是 F 的功能空间,F 是可能的 CART 的集合。上述模型的目标函数由下式给出:

其中,第一项是损失函数,第二项是正则化参数。现在,我们不是一次性学习这棵树,这会使优化变得更加困难,而是应用加法策略,最小化我们所学的损失,并添加一个新树,总结如下:

上述模型的目标函数可以定义为:

![obj^{(t)} = \sum_{i=1}^n (y_{i} - (\hat{y}_{i}^{(t-1)} + f_t(x_i)))^2 + \sum_{i=1}^t\Omega(f_i) \\ = \sum_{i=1}^n [2(\hat{y}_i^{(t-1)} - y_i)f_t(x_i) + f_t(x_i)^2] + \Omega(f_t) + constant](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/XGBoost_6.png "由 QuickLaTeX.com 渲染")
现在,让我们应用泰勒级数展开到二阶:
其中 g_i 和 h_i 可以定义为:

简化和删除常数:
![\sum_{i=1}^n [g_{i} f_{t}(x_i) + \frac{1}{2} h_{i} f_{t}^2(x_i)] + \Omega(f_t)](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/XGBoost_9.png "由 QuickLaTeX.com 渲染")
现在,我们定义正则化项,但首先我们需要定义模型:

这里,w 是树的叶子上的得分向量,q 是将每个数据点分配给相应叶子的函数,T 是叶子的数量。然后,正则化项定义为:

现在,我们的目标函数变为:
![obj^{(t)} \approx \sum_{i=1}^n [g_i w_{q(x_i)} + \frac{1}{2} h_i w_{q(x_i)}^2] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2\\ = \sum^T_{j=1} [(\sum_{i\in I_j} g_i) w_j + \frac{1}{2} (\sum_{i\in I_j} h_i + \lambda) w_j^2 ] + \gamma T](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/XGBoost_12.png "由 QuickLaTeX.com 渲染")
现在,我们简化上面的表达式:
![obj^{(t)} = \sum^T_{j=1} [G_jw_j + \frac{1}{2} (H_j+\lambda) w_j^2] +\gamma T](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/XGBoost_13.png "由 QuickLaTeX.com 渲染")
在哪里,

在这个方程中,w_j 是相互独立的,最好的 对于给定的结构 q(x),我们可以得到的最佳目标缩减是:
对于给定的结构 q(x),我们可以得到的最佳目标缩减是:

其中,γ 是剪枝参数,即执行拆分的最小信息增益。
现在,我们尝试衡量这棵树的好坏,我们不能直接优化这棵树,我们将尝试一次优化一层树。具体来说,我们尝试将一片叶子分成两片叶子,它得到的分数是
![Gain = \frac{1}{2} \left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right] - \gamma](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/XGBoost_17.png "由 QuickLaTeX.com 渲染")
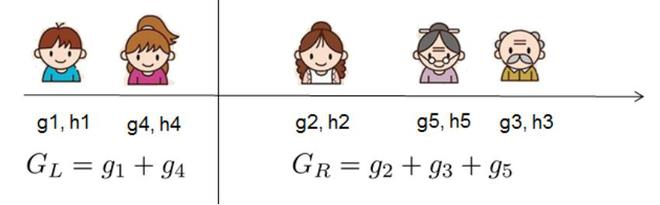
信息增益的计算
例子
让我们考虑一个示例数据集:Years of Experience Gap Annual salary (in 100k) 1 N 4 1.5 Y 4 2.5 Y 5.5 3 N 7 5 N 7.5 6 N 8
- 首先我们取基础学习者,默认情况下基础模型总是取平均工资,即
(100k)。现在,我们计算残差值:
| Years of Experience | Gap | Annual salary (in 100k) | Residuals |
|---|---|---|---|
| 1 | N | 4 | -2 |
| 1.5 | Y | 4 | -2 |
| 2.5 | Y | 5.5 | -0.5 |
| 3 | N | 7 | 1 |
| 5 | N | 7.5 | 1.5 |
| 6 | N | 8 | 2 |
- 现在,让我们考虑决策树,我们将根据经验 <=2 或其他方式拆分数据。

- 现在,让我们计算左侧和右侧的相似度度量。因为,这是回归问题,相似性度量将是:

其中,λ = 超参数
对于分类问题:

其中,P_r = 右侧任一左侧的概率。让我们来 ,左侧的相似度度量:
,左侧的相似度度量:
 和右侧。
和右侧。
 对于顶部分支:
对于顶部分支:
 .
.
- 现在,从这种拆分中获得的信息是:

同样,我们可以尝试多次拆分并计算信息增益。我们将采用信息增益最高的分割。现在让我们来获取这些信息。此外,如果存在间隙,我们将拆分决策树。
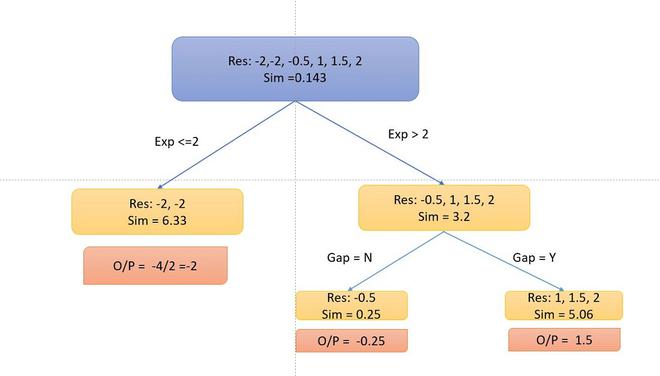
- 现在,您可以注意到我没有分裂到左侧,因为信息增益变为负数。因此,我们只在右侧执行拆分。
- 为了计算特定的输出,我们遵循决策树乘以学习率 α(我们取 0.5)并加上前一个学习器(第一棵树的基础学习器),即数据点 1:o/p = 6 + 0.5 *-2 =5。所以我们的桌子变成了。
- 类似地,该算法产生不止一个决策树并将它们相加组合以生成更好的估计
优化改进
系统优化:
- 正则化:由于决策的集成,树有时会导致非常复杂。 XGBoost 使用 Lasso 和 Ridge Regression 正则化来惩罚高度复杂的模型。
- 并行化和缓存块:在XGboost中,我们不能并行训练多棵树,但它可以并行生成树的不同节点。为此,需要按顺序对数据进行排序。为了降低排序的成本,它将数据存储在块中。它以压缩列格式存储数据,每列按相应的特征值排序。此开关通过抵消计算中的任何并行化开销来提高算法性能。
- 树修剪: XGBoost 使用 max_depth 参数指定分支分裂的停止标准,并开始向后修剪树。这种深度优先的方法显着提高了计算性能。
- Cache-Awareness 和 Out-of-score 计算:该算法旨在有效利用硬件资源。这是通过缓存感知来实现的,方法是在每个线程中分配内部缓冲区来存储梯度统计信息。诸如“核外计算”等进一步增强功能可优化可用磁盘空间,同时处理不适合内存的大数据帧。在核外计算中,Xgboost 尝试通过压缩数据集来最小化它。
- 稀疏性感知: XGBoost可以处理可能由预处理步骤或缺失值生成的稀疏数据。它使用一种特殊的拆分查找算法,该算法被合并到其中,可以处理不同类型的稀疏模式。
- 加权分位数草图: XGBoost 内置了分布式加权分位数草图算法,可以更轻松地在加权数据集中有效地找到最佳分割点。
- 交叉验证:XGboost 实现带有内置的交叉验证方法。当数据集不是那么大时,这有助于算法防止过度拟合,
参考:
- XGboost 纸
- XGboost 文档