XGBoost 回归
回归问题的结果是连续的或实数值。一些常用的回归算法是线性回归和决策树。回归中涉及多个指标,例如均方根误差 (RMSE) 和均方误差 (MAE)。这些是 XGBoost 模型的一些关键成员,每个都扮演着重要的角色。
- RMSE:它是均方误差 (MSE) 的平方根。
- MAE:它是实际差异和预测差异的绝对总和,但在数学上缺乏,这就是为什么它很少使用,与其他指标相比。
XGBoost 是一种用于构建监督回归模型的强大方法。可以通过了解其(XGBoost)目标函数和基础学习器来推断该陈述的有效性。
目标函数包含损失函数和正则化项。它讲述了实际值和预测值之间的差异,即模型结果与实际值的差距。 XGBoost 中回归问题最常见的损失函数是reg:linear ,二元分类的损失函数是reg:logistics 。
集成学习涉及训练和组合单个模型(称为基础学习器)以获得单个预测,XGBoost 是集成学习方法之一。 XGBoost 期望基础学习器在余数上一致不好,这样当所有预测结合起来时,坏预测会被抵消,更好的预测相加形成最终的好预测。
# Necessary imports
import numpy as np
import pandas as pd
import xgboost as xg
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
# Load the data
dataset = pd.read_csv("boston_house.csv")
X, y = dataset.iloc[:, :-1], dataset.iloc[:, -1]
# Splitting
train_X, test_X, train_y, test_y = train_test_split(X, y,
test_size = 0.3, random_state = 123)
# Instantiation
xgb_r = xg.XGBRegressor(objective ='reg:linear',
n_estimators = 10, seed = 123)
# Fitting the model
xgb_r.fit(train_X, train_y)
# Predict the model
pred = xgb_r.predict(test_X)
# RMSE Computation
rmse = np.sqrt(MSE(test_y, pred))
print("RMSE : % f" %(rmse))
输出:
129043.2314
代码:线性基学习器
# Necessary imports
import numpy as np
import pandas as pd
import xgboost as xg
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
# Load the data
dataset = pd.read_csv("boston_house.csv")
X, y = dataset.iloc[:, :-1], dataset.iloc[:, -1]
# Splitting
train_X, test_X, train_y, test_y = train_test_split(X, y,
test_size = 0.3, random_state = 123)
# Train and test set are converted to DMatrix objects,
# as it is required by learning API.
train_dmatrix = xg.DMatrix(data = train_X, label = train_y)
test_dmatrix = xg.DMatrix(data = test_X, label = test_y)
# Parameter dictionary specifying base learner
param = {"booster":"gblinear", "objective":"reg:linear"}
xgb_r = xg.train(params = param, dtrain = train_dmatrix, num_boost_round = 10)
pred = xgb_r.predict(test_dmatrix)
# RMSE Computation
rmse = np.sqrt(MSE(test_y, pred))
print("RMSE : % f" %(rmse))
输出:
124326.24465
注意:需要将数据集转换为DMatrix。它是 XGBoost 的创建者制作的优化数据结构。它为封装提供了性能和效率提升。
损失函数还负责分析模型的复杂性,如果模型变得更复杂,则需要对其进行惩罚,这可以使用正则化来完成。它通过 LASSO (L1) 和 Ridge (L2) 正则化来惩罚更复杂的模型,以防止过度拟合。最终目标是找到简单而准确的模型。
正则化参数如下:
- gamma:允许发生分裂的最小损失减少。伽玛值越高,分裂越少。
alpha :叶子权重的 L1 正则化,值越大,正则化越多,这导致基学习器中的许多叶子权重变为 0。 - lamba :叶权重的 L2 正则化,这比 L1 更平滑 nd 导致叶权重平滑减小,与 L1 不同,L1 对叶权重实施强约束。
以下是有助于为回归构建 XGBoost 树的公式。
第 1 步:计算相似度分数,它有助于树的生长。
Similarity Score = (Sum of residuals)^2 / Number of residuals + lambda
步骤 2:计算增益以确定如何拆分数据。
Gain = Left tree (similarity score) + Right (similarity score) - Root (similarity score)
第 3 步:通过计算 Gain 和 gamma 之间的差异(用户定义的树复杂度参数)来修剪树
Gain - gamma
如果结果为正数,则不要修剪,如果结果为负数,则修剪并再次从树的下一个增益值中减去 gamma。
第 4 步:计算剩余叶子的输出值
Output value = Sum of residuals / Number of residuals + lambda
注意:如果 lambda 的值大于 0,则会通过缩小相似度分数导致更多的修剪,并导致叶子的输出值更小。
让我们看一下寻找合适的输出值以最小化损失函数所涉及的数学部分
对于分类和回归,XGBoost 以通常为 0.5 的初始预测开始,如下图所示。
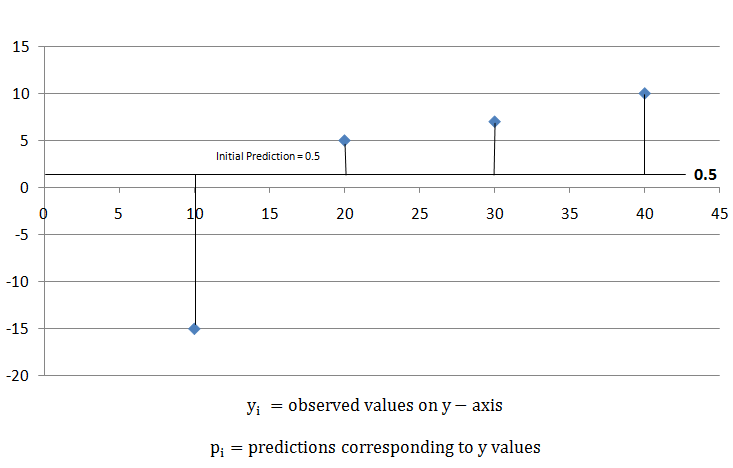
要确定预测有多好,请使用以下公式计算损失函数, 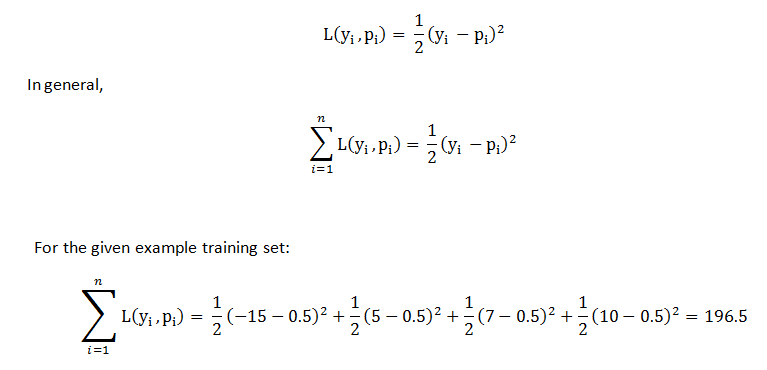
对于给定的示例,结果为 196.5。稍后,我们可以应用此损失函数并比较结果,并检查预测是否有所改善。
XGBoost 使用这些损失函数通过最小化以下方程来构建树: 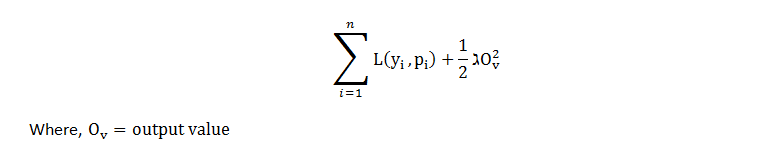
方程的第一部分是损失函数,方程的第二部分是正则化项,最终目标是最小化整个方程。
为了优化第一棵树的输出值,我们编写如下等式,将 p(i) 替换为初始预测和输出值,并让 lambda = 0 以进行更简单的计算。现在方程看起来像, 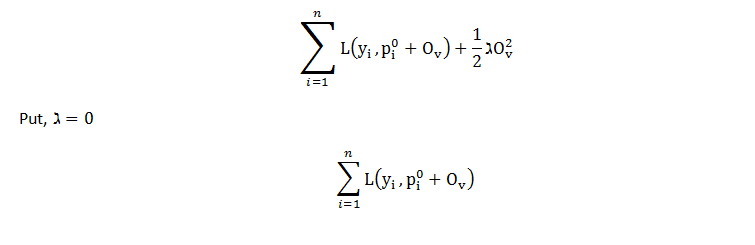
之前计算过初始预测的损失函数,结果为196.5 。
因此,对于输出值 = 0 ,损失函数= 196.5 。类似地,如果我们绘制输出值 = -1、损失函数= 203.5 和输出值 = +1、损失函数= 193.5 的点,以此类推其他输出值,如果我们在图中绘制它。我们得到一个类似抛物线的结构。这是方程作为输出值的函数的图。 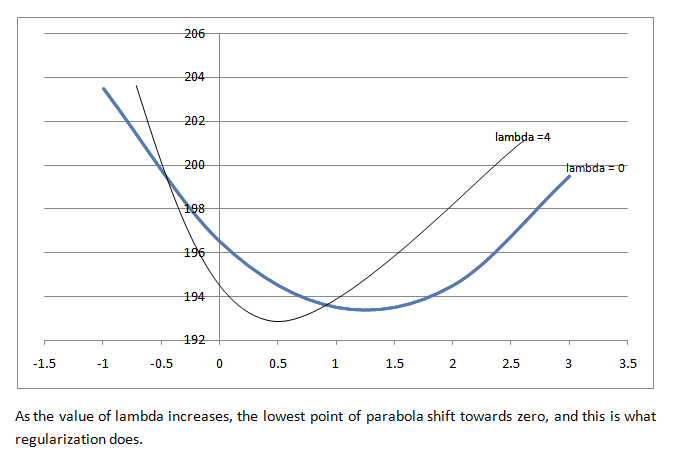
如果 lambda = 0,则最佳输出值位于导数为零的抛物线底部。 XGBoost 使用二阶泰勒近似进行分类和回归。包含输出值的损失函数可以近似如下: 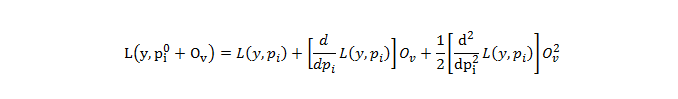
第一部分是损失函数,第二部分是损失函数的一阶导数,第三部分是损失函数的二阶导函数。一阶导数与o Gradient Descent有关,所以这里XGBoost用'g'表示一阶导数,二阶导数与Hessian有关,所以在XGBoost中用'h'表示。在等式中插入相同的内容: 
删除不包含输出值项的项,现在通过以下步骤最小化剩余函数:
- 取输出值的导数。
- 设置导数等于 0(求解抛物线的最低点)
- 求解输出值。
- g(i) = 负残差
- h(i) = 残差数
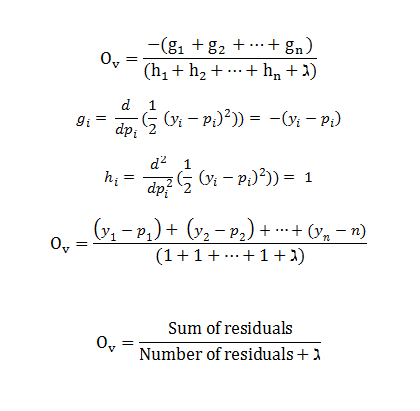
这是回归中 XGBoost 的输出值公式。它给出了抛物线最低点的 x 轴坐标。
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。