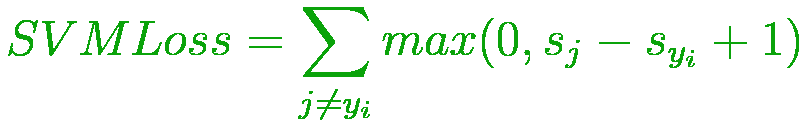损失函数估计特定算法对提供的数据进行建模的程度。根据学习任务的类型,损失函数分为两类:
- 回归模型:预测连续值。
- 分类模型:根据一组有限的分类值预测输出。
回归损失:
- 均方误差
也称为二次损失或L2损失。
它是预测值与实际观测值之间平方差的平均值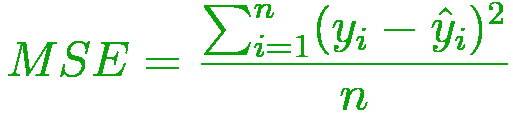
where, i - ith training sample in a dataset n - number of training samples y(i) - Actual output of ith training sample y-hat(i) - Predicted value of ith traing sample - 平均绝对误差
也称为L1损失。
它是预测和实际观测值之间绝对差之和的平均值。
- 平均偏差误差
与MSE相同。它的准确性较差,但可以得出模型具有正偏差还是负偏差的结论。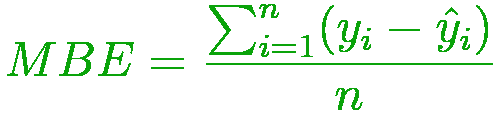
- 胡贝尔损失
也称为平滑平均绝对误差。与MSE相比,它对数据离群值更不敏感,并且在0时也可微分。这是一个绝对错误,当错误很小时,它将变成二次方。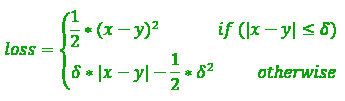
分类损失:
- 交叉熵损失
也称为负对数可能性。它是分类中常用的损失函数。交叉熵损失随着预测概率与实际标记的偏离而发展。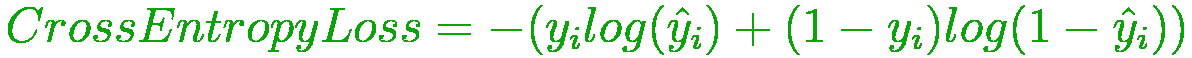
- 铰链损失
也称为多类SVM损失。铰链损失适用于最大利润率分类,主要用于支持向量机。它是在凸优化器中使用的凸函数。