ALBERT – 用于监督学习的轻型 BERT
BERT 是由谷歌 AI 的研究人员于 2018 年提出的。BERT 在 NLP 中创造了一种类似于 2012 年计算机视觉中 AlexNet 引起的转换的东西。它允许人们利用可用于训练模型的大量文本数据以自我监督的方式。
ALBERT 是由 Google Research 的研究人员于 2019 年提出的。 本文的目标是通过使用不同的技术,如参数共享、嵌入矩阵的分解、句间连贯性损失来改进 BERT 架构的训练和结果。
模型架构:
ALBERT 架构的主干类似于 BERT,后者是具有 GELU(高斯误差线性单元)激活函数的编码器层。但是,以下是 ALBERT 中存在但 BERT 中不存在的三个主要变化。
- 嵌入矩阵的因式分解:在 BERT 模型及其改进(如 XLNet 和 ROBERTa)中,输入层嵌入和隐藏层嵌入具有相同的大小。但是在这个模型中,作者分离了两个嵌入矩阵。这是因为输入级嵌入(E)只需要改进上下文无关的学习,而隐藏级嵌入(H)需要上下文相关的学习。与 BERT 相比,此步骤导致参数减少 80%,但性能略有下降。
- 跨层参数共享:该模型的作者还提出了模型不同层之间的参数共享,以提高效率并减少冗余。该论文提出,由于之前版本的 BERT、XLNet和 ROBERTa 的编码器层相互堆叠,导致模型在不同层上学习类似的操作。作者在本文中提出了三种类型的参数共享:
- 仅共享前馈网络参数
- 只分享注意力参数
- 共享所有参数。除非另有说明,作者使用的默认设置。
上述步骤导致参数总数减少了 70%。
- Inter Sentence Coherence Prediction:与BERT类似,ALBERT在训练中也使用了Masked Language模型。然而,ALBERT 没有使用 NSP(下一句预测)损失,而是使用了一种称为 SOP(句子顺序预测)的新损失。 NSP 是一种二元分类损失,用于预测原始文本中两个片段是否连续出现,这种损失的缺点是它检查连贯性以及识别下一个句子的主题。然而,SOP 只寻找句子的连贯性。
ALBERT 有 4 种不同的型号尺寸,Model Size Parameters Encoder Layers (L) Embedding (E) Hidden units (H) BERT Base 108 M 12 768 768 Large 334 M 24 1024 1024 ALBERT Base 12 M 12 128 768 Large 18 M 24 128 1024 X Large 60 M 24 128 2048 XX Large 235 M 12 128 4096
从上表中我们可以看出,由于作者在架构中进行了上述更改,与相应的 BERT 模型相比,ALBERT 模型的参数大小更小。例如,BERT base 的参数比 ALBERT base 多 9 倍,BERT Large 的参数比 ALBERT Large 多 18 倍。
使用的数据集:
与 BERT 类似,ALBERT 也在英文维基百科和 Book CORPUS 数据集上进行了预训练,这两个数据集总共包含 16 GB 的未压缩数据。
执行:
- 在此实现中,我们将使用使用 TF-Hub 和 ALBERT GitHub 存储库的预训练 ALBERT 模型。我们将在 GLUE 基准测试的 Microsoft Research Paraphrase Corpus (MRPC) 数据集上运行模型。
Python3
# Clone ALBERT Repo
! git clone https://github.com/google-research/albert
# Install Requiremtns of ALBERT
! pip install -r albert/requirements.txt
# clone GLUE repo into a folder
! test -d download_glue_repo ||
git clone https://gist.github.com/60c2bdb54d156a41194446737ce03e2e.git glue_repo
# Download MRPC dataset
!python glue_repo/download_glue_data.py --data_dir=/content/MRPC --tasks='MRPC'
# Describe the URL of TFhub ALBERT BASE model
ALBERT_MODEL_HUB = 'https://tfhub.dev/google/albert_base/3'
# Fine Tune ALBERT classifier on MRPC dataset
# To select best hyperparameter of any task of GLUE
# benchamrk look into run_glue.sh
!python -m albert.run_classifier \
--data_dir=MRPC/ \
--output_dir=output/ \
--albert_hub_module_handle=$ALBERT_MODEL_HUB \
--spm_model_file="from_tf_hub" \
--do_train=False \
--do_eval=True \
--do_predict=True \
--max_seq_length=512 \
--optimizer=adamw \
--task_name=MRPC \
--warmup_step=200 \
--learning_rate=2e-5 \
--train_step=800 \
--save_checkpoints_steps=100 \
--train_batch_size=32结果与结论:
尽管参数数量少得多,但 ALBERT 已经实现了许多 NLP 任务的最新技术。以下是 ALBERT 在 GLUE 基准数据集上的结果。阿尔伯
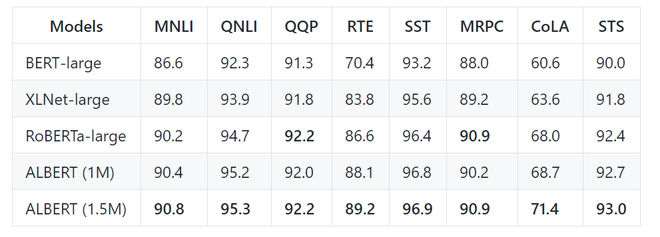
ALBERT 在 GLUE 基准测试中与其他模型相比的结果。
以下是 ALBERT-xxl 模型在 SQuAD 和 RACE 基准数据集上的结果。
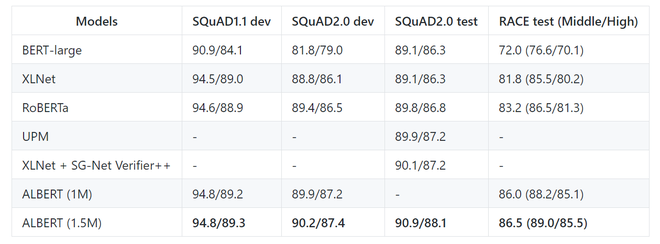
在这里,ALBERT (1M) 代表模型用 1M 步训练,而 ALBERT 1.5M 代表模型用 1.5M epoch 训练。
截至目前,作者还发布了新版本的 ALBERT (V2),与 V1 相比,BASE、LARGE、X-LARGE 模型的平均准确率有所提高。Version Size Average Score ALBERT V2 Base 82.3 Large 85.7 X-Large 87.9 XX-Large 90.9 ALBERT V1 Base 80.1 Large 82.4 X-Large 85.5 XX-Large 91.0
参考:
- 艾伯特模型纸
- 艾伯特 GitHub 存储库