概率密度估计和最大似然估计
先决条件:概率分布
概率密度:假设随机变量 x 具有概率分布 p(x)。随机变量的结果与其概率之间的关系称为概率密度。
问题是我们并不总是知道随机变量的完整概率分布。这是因为我们只使用一小部分观察结果来推导出结果。这个问题被称为概率密度估计,因为我们只使用观察的随机样本来找到整个样本空间的一般密度。
概率密度函数(PDF)
PDF 是一种函数,它告诉子样本空间中的随机变量落在特定值范围内的概率,而不仅仅是一个值。它告诉随机变量子空间中值的范围与整个样本的范围相同的可能性。
根据定义,如果 X 是任何连续随机变量,则函数f(x) 称为概率密度函数,如果:

where,
a -> lower limit
b -> upper limit
X -> continuous random variable
f(x) -> probability density function涉及步骤:
Step 1 - Create a histogram for the random set of observations to understand the
density of the random sample.
Step 2 - Create the probability density function and fit it on the random sample.
Observe how it fits the histogram plot.
Step 3 - Now iterate steps 1 and 2 in the following manner:
3.1 - Calculate the distribution parameters.
3.2 - Calculate the PDF for the random sample distribution.
3.3 - Observe the resulting PDF against the data.
3.4 - Transform the data to until it best fits the distribution. 拟合后的不同随机样本的直方图大部分应该与整个总体的直方图匹配。
密度估计:它是通过检查来自该总体的随机数据样本来找出整个总体的密度的过程。实现密度估计的最佳方法之一是使用直方图。
参数密度估计
正态分布有两个给定的参数,均值和标准差。我们计算从这个总体中抽取的随机样本的样本均值和标准差来估计随机样本的密度。之所以将其称为“参数”,是因为观测值与其概率之间的关系可能因两个参数的值而异。
现在,重要的是要了解这个随机样本的均值和标准差不会与整个总体的平均值和标准差相同,因为它的规模很小。参数密度估计的示例图如下所示。
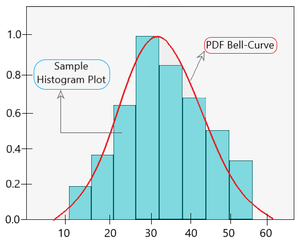
PDF 拟合一个峰值的直方图
非参数密度估计
在某些情况下,PDF 可能不适合随机样本,因为它不遵循正态分布(即图中不是一个峰而是多个峰)。在这里,不是使用均值和标准差等分布参数,而是使用特定算法来估计概率分布。因此,它被称为“非参数密度估计” 。
最常见的非参数方法之一称为核密度估计。在这里,目标是使用下面给出的等式计算未知密度 f h (x):

where,
K -> kernel (non-negative function)
h -> bandwidth (smoothing parameter, h > 0)
Kh -> scaled kernel
fh(x) -> density (to calculate)
n -> no. of samples in random sample.下面给出了非参数密度估计的示例图。
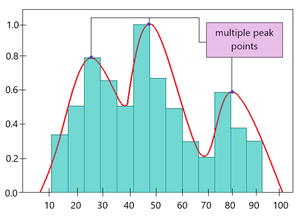
基于 KDE 的样本直方图上的 PDF 图
概率分布估计的问题
概率分布估计依赖于找到最佳 PDF 并准确确定其参数。但是我们考虑的随机数据样本非常小。因此,确定使用什么参数和概率分布函数变得非常困难。为了解决这个问题,使用了最大似然估计。
最大似然估计
它是一种确定正态分布随机样本数据的参数(均值、标准差等)的方法,或者是在随机样本数据上找到最佳拟合 PDF 的方法。这是通过最大化似然函数来完成的,以便 PDF 拟合随机样本。另一种看待它的方式是 MLE函数给出了平均值,随机样本的标准偏差与整个样本的标准偏差最相似。
NOTE: MLE assumes that all PDFs are a likely candidate to being the best fitting curve. Hence, it is computationally expensive method.
直觉:
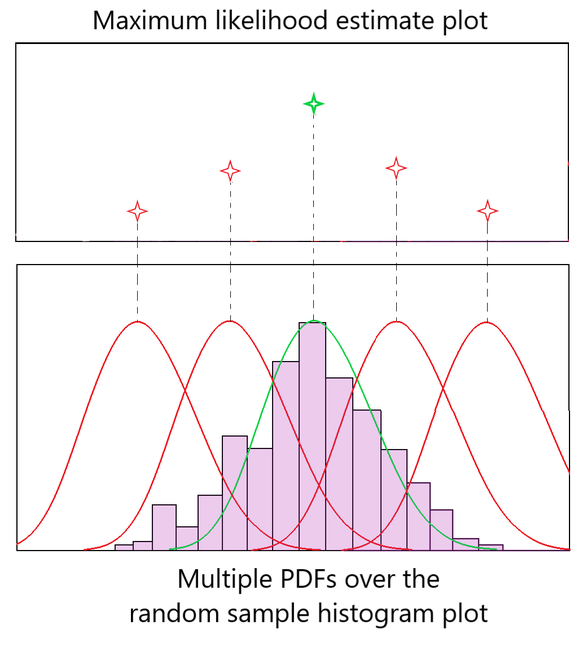
图 1:MLE 直觉
图 1 显示了在随机样本数据上拟合 PDF 钟形曲线的多次尝试。红色钟形曲线表示拟合较差的 PDF,而绿色钟形曲线表示拟合数据最合适的 PDF。我们通过检查与每个 PDF 对应的最大似然估计图中的值来获得最佳钟形曲线。
如图 1 所示,红色图不太适合正态分布,因此它们的“似然估计”也较低。绿色 PDF 曲线具有最大似然估计,因为它完美地拟合了数据。这就是最大似然估计方法的工作原理。
涉及的数学
在直觉中,我们讨论了似然值在确定最佳 PDF 曲线中的作用。让我们了解 MLE 方法中涉及的数学。
我们根据条件概率计算可能性。请参阅下面给出的等式。
where,
L -> Likelihood value
F -> Probability distribution function
P -> Probability
X1, X2, ... Xn -> random sample of size n taken from the whole population.
x1, x2, ... xn -> values that these random sample (Xi) takes when determining the PDF.
Π -> product from 1 to n.在上面给出的等式中,我们试图通过计算每个 X i的联合概率来确定似然值,该概率取特定 PDF 中涉及的特定值 x i 。现在,由于我们正在寻找最大似然值,我们将似然函数wrt P 微分并将其设置为 0,如下所示。

通过这种方式,我们可以获得对随机样本数据具有最大拟合可能性的 PDF 曲线。
但是,如果仔细观察,区分 L 和 P 并不是一件容易的事,因为似然函数中的所有概率都是乘积。因此,计算在计算上变得昂贵。为了解决这个问题,我们取似然函数L 的对数。
对数似然

由于 Log函数的递增性质,取似然函数的对数给出与之前相同的结果。但是现在,由于对数的性质,它变得更少计算:
因此,等式变为:
现在,我们可以轻松区分 log L wrt P 并获得所需的结果。如有任何疑问/疑问,请在下方评论。