📌 相关文章
- 机器学习中的线性回归
- 机器学习中的线性回归(1)
- 机器学习中的简单线性回归(1)
- 机器学习中的简单线性回归
- ML |线性回归的波士顿住房卡格勒挑战(1)
- ML |线性回归的波士顿住房卡格勒挑战
- 机器学习-多元线性回归(1)
- 机器学习-多元线性回归
- Python线性回归
- Python线性回归(1)
- python中的线性回归(1)
- python 线性回归 - Python (1)
- scikit 学习线性回归 - Python (1)
- 机器学习中的回归分析(1)
- 机器学习中的回归分析
- python代码示例中的线性回归
- R线性回归
- R-线性回归
- 线性回归 (1)
- R线性回归(1)
- R-线性回归(1)
- 机器学习中的逻辑回归
- 机器学习中的逻辑回归(1)
- 机器学习中的回归与分类
- scikit 学习线性回归 - Python 代码示例
- python 线性回归 - Python 代码示例
- 运行回归时的挑战 (1)
- 机器学习-多项式回归(1)
- 机器学习-多项式回归
📜 Python线性回归的波士顿房屋Kaggle挑战 | 机器学习 Machine Learning
📅 最后修改于: 2020-04-23 05:56:29 🧑 作者: Mango
波士顿房屋数据:此数据集取自StatLib库,由卡内基梅隆大学维护。该数据集涉及房屋城市波士顿的房价。提供的数据集具有506个实例和13个特征。
数据集描述取自:


让我们建立线性回归模型,预测房价
输入库和数据集。
# 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
from sklearn.datasets import load_boston
boston = load_boston()输入波士顿数据的形状并获取feature_names
boston.data.shape
boston.feature_names

将数据从nd-array转换为dataframe并将特征名称添加到数据
data = pd.DataFrame(boston.data)
data.columns = boston.feature_names
data.head(10)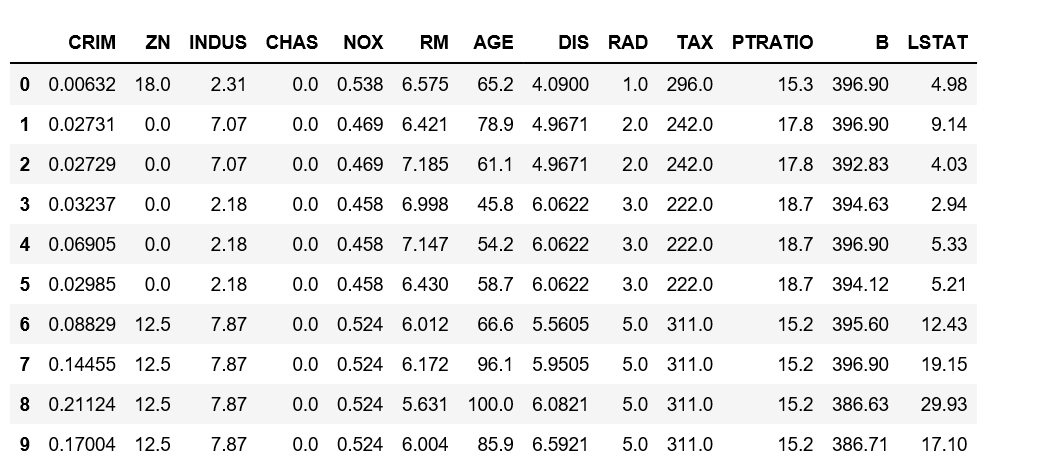

在数据集中添加“Price”列
# 在数据中添加“Price"(目标)列
boston.target.shape
data['Price'] = boston.target
data.head()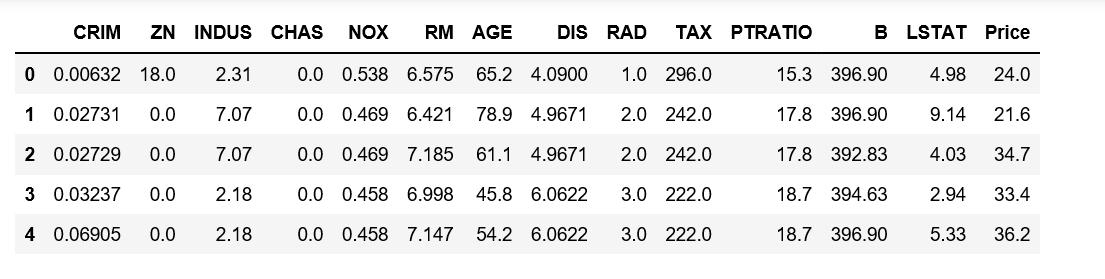

波士顿数据集的描述
data.describe()

波士顿数据集的信息
data.info()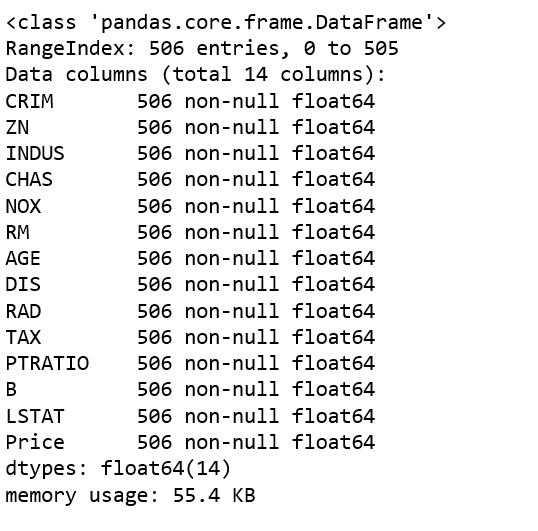

获取输入和输出数据,并将数据进一步拆分为训练和测试数据集。
# 输入数据
x = boston.data
# 输出数据
y = boston.target
# 将数据拆分为训练和测试数据集.
from sklearn.cross_validation import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size =0.2,
random_state = 0)
print("xtrain shape : ", xtrain.shape)
print("xtest shape : ", xtest.shape)
print("ytrain shape : ", ytrain.shape)
print("ytest shape : ", ytest.shape)

将线性回归模型应用于数据集并预测价格。
# 将多元线性回归模型拟合到训练模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(xtrain, ytrain)
# 预测测试集结果
y_pred = regressor.predict(xtest)绘制散点图以显示预测结果“ ytrue”值与“ y_pred”值
# 绘制散点图以显示“ytrue"值与“y_pred"值
plt.scatter(ytest, y_pred, c = 'green')
plt.xlabel("Price: in $1000's")
plt.ylabel("Predicted value")
plt.title("True value vs predicted value : Linear Regression")
plt.show()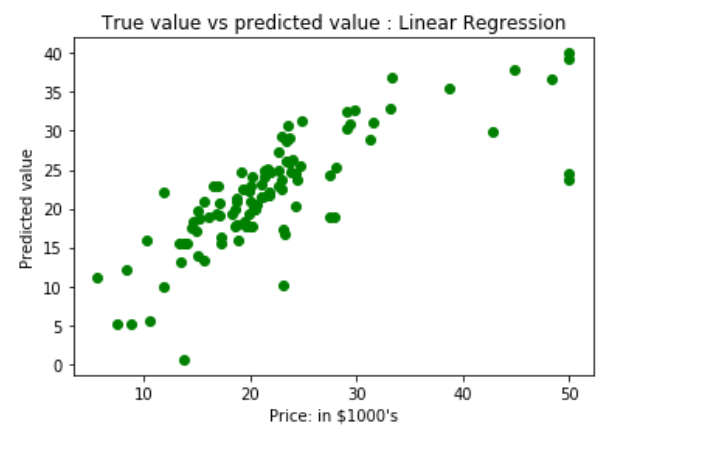

线性回归的结果,即均方误差。
# Results of Linear Regression.
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(ytest, y_pred)
print("Mean Square Error : ", mse)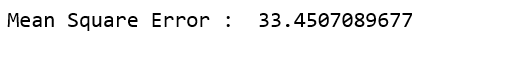



根据结果,我们的模型只有66.55%的准确度。因此,准备好的模型对于预测房屋价格不是很好。可以使用许多其他可能的机器学习算法和技术来改善预测结果。