数据挖掘中的主成分分析
降维是有效分析海量高维数据集的必要步骤。它可能是数据挖掘中用于分析和可视化高维数据的主要目标,也可能是启用其他分析(如聚类)的中间步骤。
主成分分析是一种数据缩减技术,可将大量相关变量转换为较小的一组相关变量,称为主成分。简单来说,主成分分析是一种从数据集中可用的大量变量中提取重要变量的方法,它从高维数据集中提取一组低维特征,目的是尽可能多地捕获信息(方差)数据。
主成分分析主要用作计算机视觉和图像压缩等各种人工智能应用中的降维技术。当数据具有大维度时,它还可以用于查找隐藏模式。使用主成分分析的一些领域是金融、数据挖掘、心理学等。
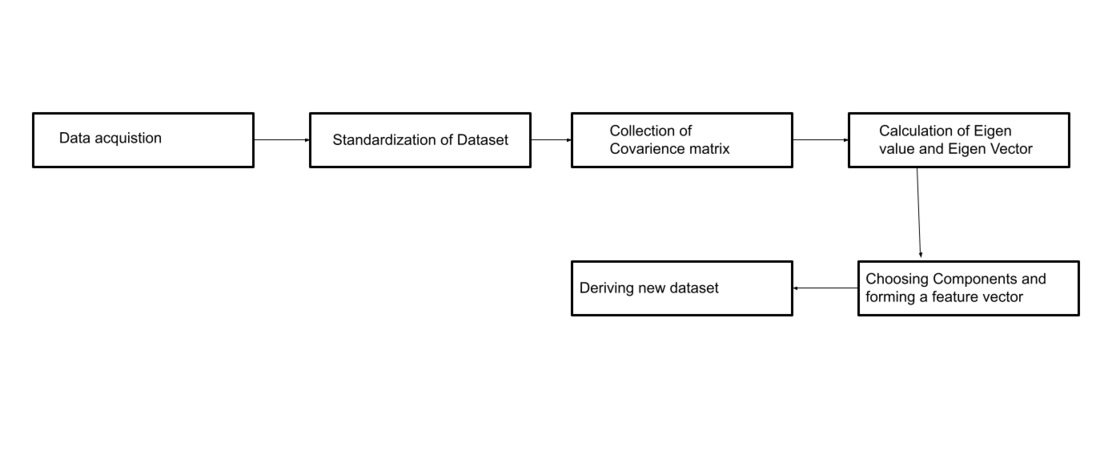
主成分分析涉及的步骤:
主成分分析的主要步骤如下:
- 标准化数据集。
- 计算数据集中特征的协方差矩阵。
- 计算协方差矩阵的特征值和特征向量。
- 对特征值及其对应的特征向量进行排序。
- 选择k个特征值组成一个特征向量矩阵。
- 变换原始矩阵。
用途:
主成分分析在数据挖掘中有很多用途,下面列出了其中的一些:
- 它用于查找数据中变量之间的相互关系。
- 它用于解释和可视化数据。
- 变量的数量减少了,这使得进一步的分析更简单。
- 它通常用于可视化种群之间的遗传距离和相关性。
好处:
- 它有助于数据压缩并删除相关特征。
- 它有助于加速其他数据挖掘算法。
- 它将高维数据转换为低维数据,从而改进并简化可视化。
缺点:
- 它可能会导致一些数据丢失。
- 它倾向于找到变量之间的线性相关性,这有时是不可取的。
- 在均值和协方差不足以定义数据集的情况下,它会失败。