📌 相关文章
- 使用Python进行主成分分析PCA(1)
- 使用Python进行主成分分析PCA
- ML |主成分分析(PCA)(1)
- ML |主成分分析(PCA)
- 使用Python主成分分析
- 使用Python主成分分析(1)
- 主成分分析 - R 编程语言(1)
- 主成分分析 - R 编程语言代码示例
- Python – 主成分分析的变体
- Python – 主成分分析的变体(1)
- pca - Python (1)
- pca python (1)
- 数据挖掘中的主成分分析(1)
- 数据挖掘中的主成分分析
- 使用 R 编程进行主成分分析
- 使用 R 编程进行主成分分析(1)
- pca - Python 代码示例
- pca python 代码示例
- 机器学习-主成分分析
- 机器学习-主成分分析(1)
- 毫升 |独立成分分析(1)
- 毫升 |独立成分分析
- Selenium的成分
- Selenium的成分(1)
- 如何用 R 制作 PCA 图(1)
- 如何用 R 制作 PCA 图
- sklearn 中的 PCA (1)
- 将 pca 应用于数据框 - C++ 代码示例
- sklearn 中的 PCA - 任何代码示例
📜 Python 主成分分析(PCA)
📅 最后修改于: 2020-04-23 11:25:42 🧑 作者: Mango
主成分分析(PCA)是一种统计过程,它使用正交变换将一组相关变量转换为一组不相关变量。PCA是探索性数据分析和预测模型的机器学习中使用最广泛的工具。此外,PCA是一种无监督的统计技术,用于检查一组变量之间的相互关系。这也被称为一般因素分析,其中回归确定一条最佳拟合线。
所需模块:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline代码1:
# 这里我们使用的是scikit学习的内置数据集
from sklearn.datasets import load_breast_cancer
# 实例化
cancer = load_breast_cancer()
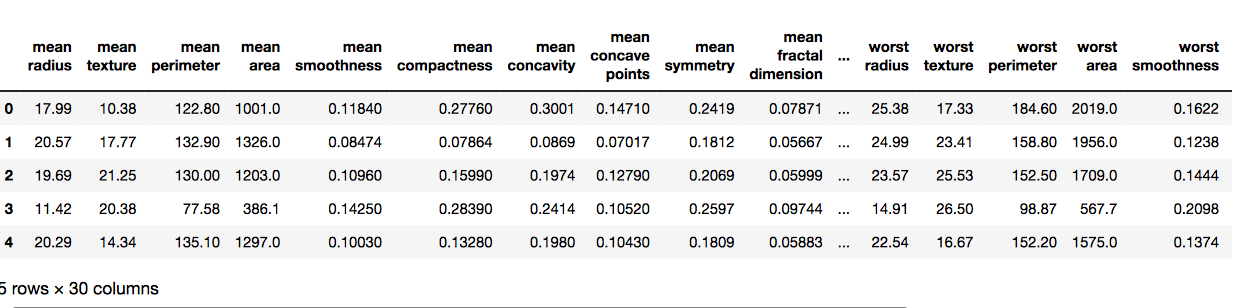
# 创建数据框
df = pd.DataFrame(cancer['data'], columns = cancer['feature_names'])
# 检查数据帧头
df.head()输出:
代码#2:
# 导入模块
from sklearn.preprocessing import StandardScaler
scalar = StandardScaler()
# 配件
scalar.fit(df)
scaled_data = scalar.transform(df)
# 导入PCA
from sklearn.decomposition import PCA
# 假设,components = 2
pca = PCA(n_components = 2)
pca.fit(scaled_data)
x_pca = pca.transform(scaled_data)
x_pca.shape输出:
#减少至569,2

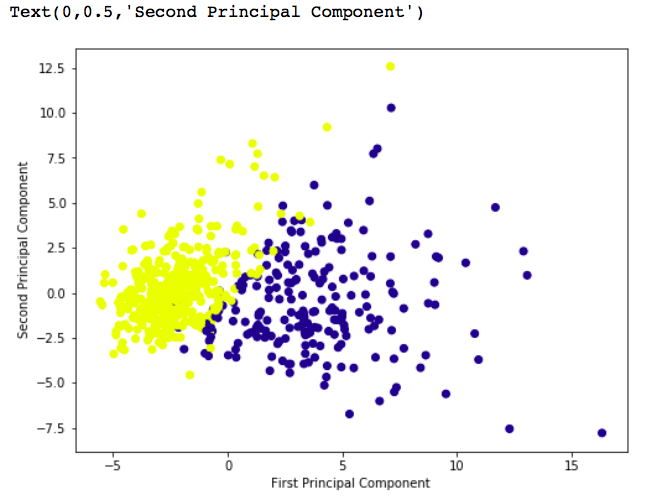
# 给出更大的plot
plt.figure(figsize =(8, 6))
plt.scatter(x_pca[:, 0], x_pca[:, 1], c = cancer['target'], cmap ='plasma')
# 标记x和y轴
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')输出:
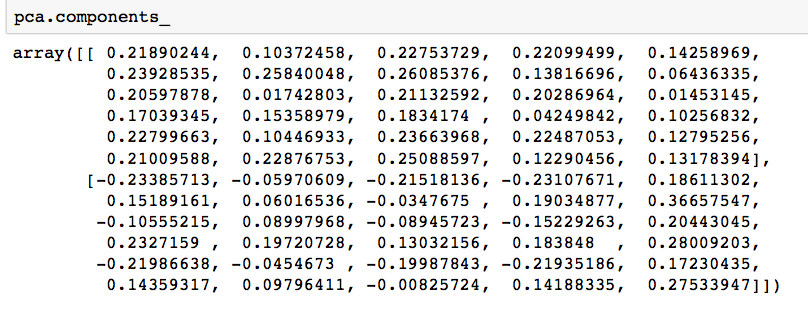
# 组件
pca.components_输出:
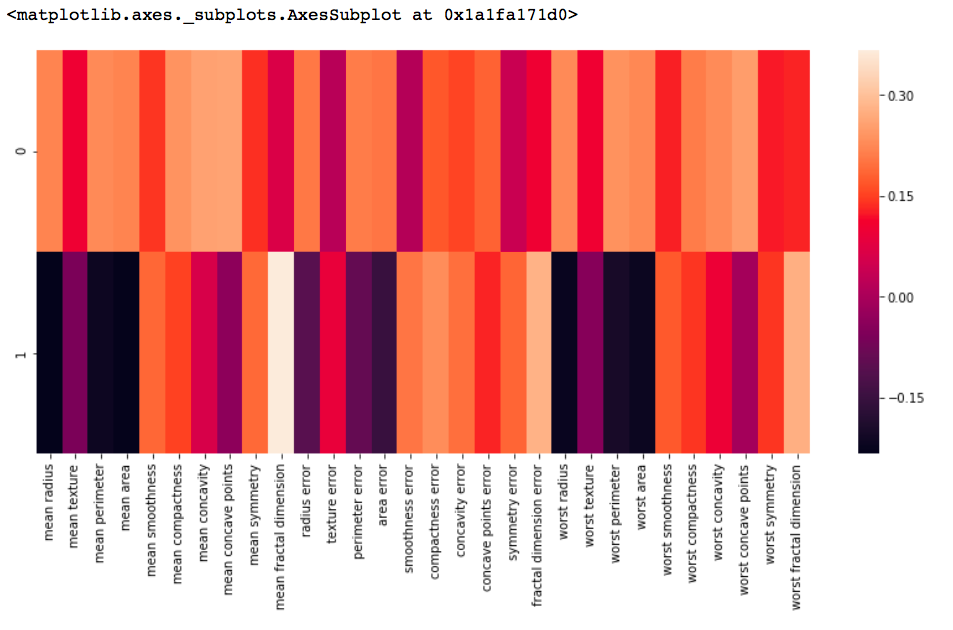
df_comp = pd.DataFrame(pca.components_, columns = cancer['feature_names'])
plt.figure(figsize =(14, 6))
# 绘制热图
sns.heatmap(df_comp)输出: