毫升 | K-Medoids 聚类与解决的例子
K-Medoids(也称为 Partitioning Around Medoid)算法由 Kaufman 和 Rousseeuw 于 1987 年提出。中心点可以定义为簇中的点,它与簇中所有其他点的相异性最小。
通过使用E = |Pi - Ci| medoid(Ci )和object(Pi )的不相似度。
The cost in K-Medoids algorithm is given as

算法:
1. Initialize: select k random points out of the n data points as the medoids.
2. Associate each data point to the closest medoid by using any common distance metric methods.
3. While the cost decreases:
For each medoid m, for each data o point which is not a medoid:
1. Swap m and o, associate each data point to the closest medoid, recompute the cost.
2. If the total cost is more than that in the previous step, undo the swap.
让我们考虑以下示例: 
如果使用上述数据点绘制图形,我们将获得以下结果: 
第1步:
让随机选择的2个中心点,所以选择k = 2并让C1 -(4, 5)和C2 -(8, 5)是两个中心点。
第 2 步:计算成本。
计算每个非中心点与中心点的相异度并制成表格: 
每个点都被分配到相异性较小的那个中心点的集群。
点1, 2, 5进入集群C1 ,点0, 3, 6, 7, 8进入集群C2 。
Cost = (3 + 4 + 4) + (3 + 1 + 1 + 2 + 2) = 20
第三步:随机选择一个非中心点,重新计算代价。
设随机选择的点为 (8, 4)。计算每个非中心点与中心点的差异 - C1 (4, 5)和C2 (8, 4)并制成表格。 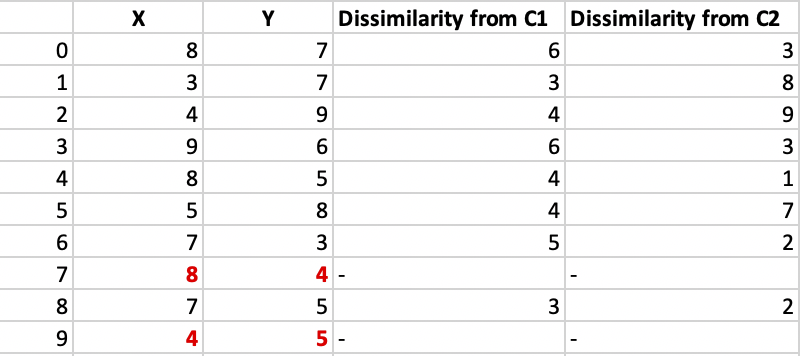
每个点都被分配到相异性较小的那个集群。因此,点1, 2, 5进入集群C1 ,点0, 3, 6, 7, 8进入集群C2 。
New cost = (3 + 4 + 4) + (2 + 2 + 1 + 3 + 3) = 22
掉期成本 = 新成本 - 先前成本 = 22 – 20 和2 >0
由于交换成本不小于零,我们撤销交换。因此(3, 4)和(7, 4)是最终的中心点。聚类将采用以下方式
时间复杂度为 .
.
好处:
- 它易于理解且易于实现。
- K-Medoid 算法速度快,收敛于固定步数。
- 与其他分区算法相比,PAM 对异常值不太敏感。
缺点:
- K-Medoid 算法的主要缺点是它不适合对非球形(任意形状)对象组进行聚类。这是因为它依赖于最小化非中心点对象和中心点(聚类中心)之间的距离——简而言之,它使用紧凑性而不是连接性作为聚类标准。
- 由于前 k 个中心点是随机选择的,因此在同一数据集上的不同运行可能会获得不同的结果。