二分K-Means算法介绍
先决条件: K 表示聚类 - 介绍
K-Means 算法有一些限制,如下所示:
- 它只能识别球形簇,即它不能识别簇是否为非球形或具有各种大小和密度。
- 它受到局部最小值的影响,并且在数据包含异常值时会出现问题。
二分 K 均值算法是对 K 均值算法的修改。它可以产生分区/层次聚类。它可以识别任何形状和大小的簇。这个算法很方便。
- 它在熵测量方面击败了 K-Means。
注意:熵测量是对正在处理的数据中随机性的测量。例子:抛硬币。如果正在处理的给定数据的熵很高,则很难从该数据中得出结论。 ]
示例 1 —假设您走进一个由许多椅子组成的大厅,然后坐在其中一个椅子上,而没有特别注意任何其他椅子,也没有考虑是否可以从您所坐的椅子上听到舞台上演讲者的声音。这种方法可以称为“K-Means”。
示例 2 —假设您走进一个由许多椅子组成的大厅。您观察所有椅子,并根据各种因素决定占用哪一张,例如您是否可以从该位置听到扬声器以及椅子是否放置在空调附近。这种方法可以称为“二等分 K 均值”。
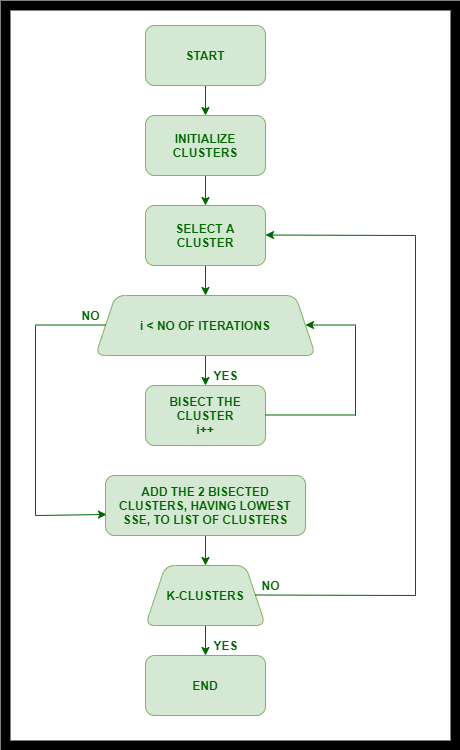
二分 K 均值算法:
- 初始化集群列表以容纳由所有点组成的集群。
- 重复
- 从集群列表中丢弃一个集群。
- { 对选定的簇执行几次“试验”二分。 }
- 对于i = 1 到试验次数做
- 使用基本 K 均值将选定的簇一分为二。
- 结束于
- 从二等分中选择总 SSE 最少的 2 个簇。
- 直到集群列表包含“K”个集群
- 该算法的工作可以浓缩为两个步骤。
- 首先,让我们假设最后阶段所需的集群数量,'K' = 3(如果没有提到,可以假设任何值)。
步骤 01:
- 所有点/对象/实例都放入 1 个集群中。
步骤 02:
- 应用 K 均值 (K=3)。集群“GFG”被分成两个集群“GFG1”和“GFG2”。尚未获得所需的集群数量。因此,'GFG1' 被进一步分为两部分(因为它具有更高的 SSE(计算 SSE 的公式在下面解释))
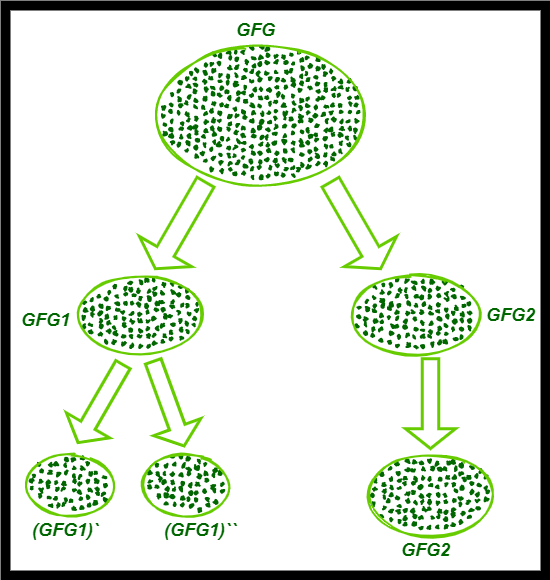
- 在上图中,当我们将集群 'GFG' 拆分为 'GFG1' 和 'GFG2' 时,我们使用上述公式分别计算了两个集群的 SSE。具有更高 SSE 的集群将被进一步拆分。具有较低 SSE 的集群相对包含较少的错误,因此不会进一步分裂。
- 在这里,如果我们计算得出,集群“GFG1”是具有较高 SSE 的集群,我们将其拆分为 (GFG1)` 和 (GFG1)`。提到最后阶段所需的集群数量为'3',我们已经获得了3个集群。
- 如果没有得到所需的簇数,我们应该继续分裂,直到产生它们。
例子:
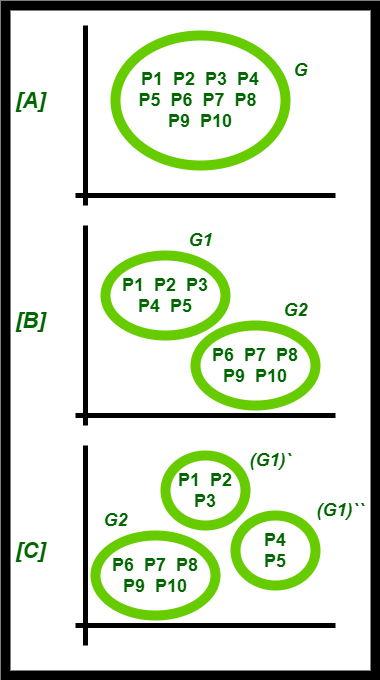
考虑一个集群 'G' = ( P1, P2, P3, P4, P5, P6, P7, P8, P9, P10 ) ,由 10 个点组成。 K=3(给定)
- 应用二分 K 均值算法,第 [A] 步中所示的集群“G”被分成两个集群——“G1”和“G2”,如第 [B] 步中所示。最后阶段所需的集群总数,即'K'=3(给定)。
- 由于尚未获得所需的集群,我们应该拆分获得的两个集群之一。
- 选择具有较高 SSE 的集群(因为具有较低 SSE 的集群错误较少)。在这里,具有较高 SSE 的集群是集群“G1”。它分别分为(G1)`和(G1)“。
- 因此,获得了所需数量的集群。