汤普森抽样简介 |强化学习
强化学习是机器学习的一个分支,也称为在线学习。它用于根据截至时间 t 的数据决定在 t+1 采取什么行动。这个概念用于人工智能应用,例如步行。强化学习的一个流行例子是国际象棋引擎。这里,代理决定响应一系列取决于板(环境)的状态移动,并且奖励可以被定义为输或赢的游戏结束。
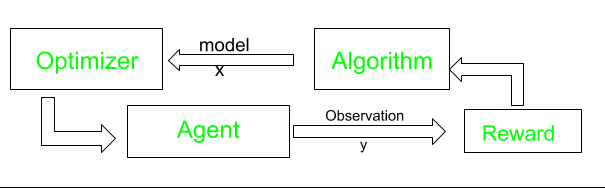
汤普森采样(后采样或概率匹配)是一种算法,用于选择解决多臂老虎机问题中探索开发困境的行动。动作被执行多次,称为探索。它使用培训信息来评估所采取的行动,而不是通过给出正确的行动来进行指导。这就是需要积极探索的原因,需要明确的试错法来寻找良好的行为。根据这些动作的结果,对机器的该动作给予奖励 (1) 或惩罚 (0)。执行进一步的操作是为了最大化可能提高未来表现的奖励。假设一个机器人必须挑选几个罐头并放入一个容器中。每次将罐头放入容器时,它都会记住遵循的步骤并训练自己以更快的速度和精度(奖励)执行任务。如果机器人无法将罐子放入容器中,它将不会记住该程序(因此不会提高速度和性能),并将被视为惩罚。
Thompson Sampling 的优势在于随着我们获得越来越多的信息而倾向于减少搜索,这模仿了问题中的理想权衡,我们希望在更少的搜索中获得尽可能多的信息。因此,当我们的数据较少时,该算法倾向于更“面向搜索”,而当我们有大量数据时,该算法更倾向于“面向搜索”。
多臂强盗问题
多臂老虎机是多臂老虎机的同义词。每个动作选择就像玩老虎机的一个杠杆,奖励是中奖的回报。通过重复的行动选择,您可以将您的行动集中在最佳杠杆上,从而最大限度地提高您的收益。每台机器根据特定于机器的平均奖励的概率分布提供不同的奖励。在不知道这些概率的情况下,赌徒必须最大化通过一系列拉臂获得的奖励总和。如果您保持对动作值的估计,那么在任何时间步,至少有一个动作的估计值最大。我们称之为贪婪的行为。这个问题的类比可以是每当用户访问网页时显示广告。武器是每次用户连接到网页时向用户显示的广告。每次用户连接到页面时都会出现。在每一轮中,我们选择一个广告向用户展示。在每一轮 n 中,广告 i 给出奖励 ri(n) ε {0, 1}:如果用户点击了广告 i,则 ri(n)=1,如果用户没有点击,则为 0。该算法的目标是最大化奖励。另一个类比是医生为一系列重病患者在实验性治疗之间进行选择。每一次行动选择都是一次治疗选择,每一次奖励都是患者的生存或幸福。
算法
一些实际应用