Pandas 中的数据结构
Pandas是一个开源库,用于轻松直观地处理关系或标记数据。它提供了用于处理数值数据和时间序列的各种数据结构和操作。它提供了一种用于清理和处理数据的工具。它是最流行的用于数据分析的Python库。在本文中,我们将学习 Pandas 数据结构。
它支持两种数据结构:
- 系列
- 数据框
系列
Pandas 是一个一维标记数组,能够保存任何类型的数据(整数、字符串、浮点数、 Python对象等)。
Syntax: pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
Parameters:
- data: array- Contains data stored in Series.
- index: array-like or Index (1d)
- dtype: str, numpy.dtype, or ExtensionDtype, optional
- name: str, optional
- copy: bool, default False
示例 1:包含 char 数据类型的系列。
Python3
import pandas as pd
# a simple char list
list = ['g', 'e', 'e', 'k', 's']
# create series form a char list
res = pd.Series(list)
print(res)Python3
import pandas as pd
# a simple int list
list = [1,2,3,4,5]
# create series form a int list
res = pd.Series(list)
print(res)Python3
import pandas as pd
dic = { 'Id': 1013, 'Name': 'MOhe',
'State': 'Maniput','Age': 24}
res = pd.Series(dic)
print(res)Python3
# import pandas as pd
import pandas as pd
# list of strings
lst = ['Geeks', 'For', 'Geeks', 'is',
'portal', 'for', 'Geeks']
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
display(df)Python3
# Python code demonstrate creating
# DataFrame from dict narray / lists
# By default addresses.
import pandas as pd
# initialise data of lists.
data = {'Name':['Tom', 'nick', 'krish', 'jack'],
'Age':[20, 21, 19, 18]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
display(df)Python3
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# select two columns
print(df[['Name', 'Qualification']])Python3
# Importing pandas as pd
from pandas import DataFrame
# Creating a data frame
Data = {'Name': ['Mohe', 'Shyni', 'Parul', 'Sam'],
'ID': [12, 43, 54, 32],
'Place': ['Delhi', 'Kochi', 'Pune', 'Patna']
}
df = DataFrame(Data, columns = ['Name', 'ID', 'Place'])
# Print original data frame
print("Original data frame:\n")
display(df)
# Selecting the product of Electronic Type
select_prod = df.loc[df['Name'] == 'Mohe']
print("\n")
# Print selected rows based on the condition
print("Selecting rows:\n")
display (select_prod)Python3
# Importing pandas as pd
from pandas import DataFrame
# Creating a data frame
Data = {'Name': ['Mohe', 'Shyni', 'Parul', 'Sam'],
'ID': [12, 43, 54, 32],
'Place': ['Delhi', 'Kochi', 'Pune', 'Patna']
}
df = DataFrame(Data, columns = ['Name', 'ID', 'Place'])
# Print original data frame
print("Original data frame:")
display(df)
print("Selected column: ")
display(df[['Name', 'ID']] )输出:

示例 2:包含 Int 数据类型的系列。
蟒蛇3
import pandas as pd
# a simple int list
list = [1,2,3,4,5]
# create series form a int list
res = pd.Series(list)
print(res)
输出:

示例 3:保存字典的系列。
蟒蛇3
import pandas as pd
dic = { 'Id': 1013, 'Name': 'MOhe',
'State': 'Maniput','Age': 24}
res = pd.Series(dic)
print(res)
输出:

数据框
Pandas DataFrame是一个二维大小可变、潜在异构的表格数据结构,带有标记的轴(行和列)。数据框是一种二维数据结构,即数据在行和列中以表格方式对齐,如电子表格或 SQL 表,或系列对象的字典。 . Pandas DataFrame 由三个主要组件组成, data 、 rows和columns 。
创建 Pandas 数据帧
在现实世界中,Pandas DataFrame 将通过从现有存储中加载数据集来创建,存储可以是 SQL 数据库、CSV 文件和 Excel 文件。 Pandas DataFrame 可以从列表、字典和字典列表等中创建。 Dataframe 可以用不同的方式创建,这里有一些我们创建数据框的方法:
示例 1:可以使用单个列表或列表列表创建 DataFrame。
蟒蛇3
# import pandas as pd
import pandas as pd
# list of strings
lst = ['Geeks', 'For', 'Geeks', 'is',
'portal', 'for', 'Geeks']
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
display(df)
输出:

示例 2:从 ndarray/lists 的 dict 创建 DataFrame。
要从 narray/list 的 dict 创建 DataFrame,所有 narray 必须具有相同的长度。如果传递了索引,则长度索引应等于数组的长度。如果未传递索引,则默认情况下,索引将为 range(n),其中 n 是数组长度。
蟒蛇3
# Python code demonstrate creating
# DataFrame from dict narray / lists
# By default addresses.
import pandas as pd
# initialise data of lists.
data = {'Name':['Tom', 'nick', 'krish', 'jack'],
'Age':[20, 21, 19, 18]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
display(df)
输出:

处理 DataFrame 中的列和行
列的选择:为了在 Pandas DataFrame 中选择一列,我们可以通过按列名调用它们来访问这些列。
蟒蛇3
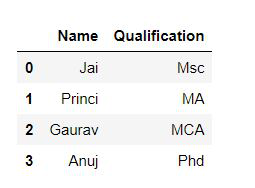
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# select two columns
print(df[['Name', 'Qualification']])
输出:
如何从 Pandas DataFrame 中选择行和列?
示例 1:选择行。
pandas.DataFrame.loc 是一个函数,用于根据提供的条件从 Pandas DataFrame 中选择行。
Syntax: df.loc[df[‘cname’] ‘condition’]
Parameters:
- df: represents data frame
- cname: represents column name
- condition: represents condition on which rows has to be selected
蟒蛇3
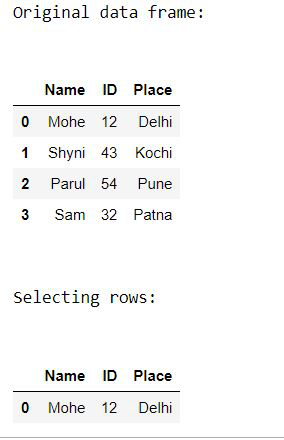
# Importing pandas as pd
from pandas import DataFrame
# Creating a data frame
Data = {'Name': ['Mohe', 'Shyni', 'Parul', 'Sam'],
'ID': [12, 43, 54, 32],
'Place': ['Delhi', 'Kochi', 'Pune', 'Patna']
}
df = DataFrame(Data, columns = ['Name', 'ID', 'Place'])
# Print original data frame
print("Original data frame:\n")
display(df)
# Selecting the product of Electronic Type
select_prod = df.loc[df['Name'] == 'Mohe']
print("\n")
# Print selected rows based on the condition
print("Selecting rows:\n")
display (select_prod)
输出:
示例 2:选择列。
蟒蛇3
# Importing pandas as pd
from pandas import DataFrame
# Creating a data frame
Data = {'Name': ['Mohe', 'Shyni', 'Parul', 'Sam'],
'ID': [12, 43, 54, 32],
'Place': ['Delhi', 'Kochi', 'Pune', 'Patna']
}
df = DataFrame(Data, columns = ['Name', 'ID', 'Place'])
# Print original data frame
print("Original data frame:")
display(df)
print("Selected column: ")
display(df[['Name', 'ID']] )
输出:
