使用分支定界算法进行特征选择
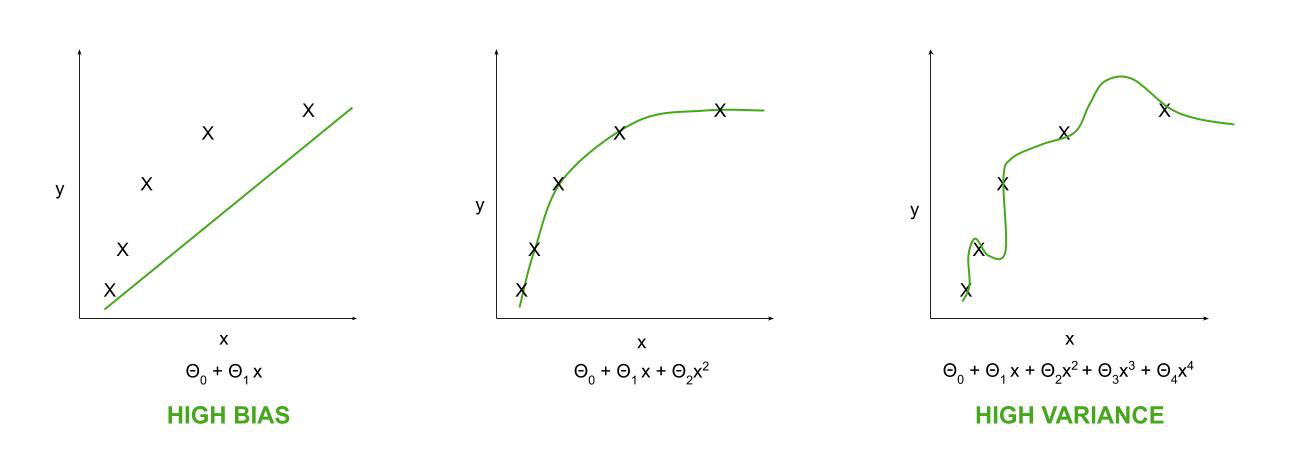
特征选择是机器学习中一个非常重要的因素。为了使算法正常工作并给出接近完美的预测,即为了提高预测模型的性能,需要进行特征选择。应删除大量功能或冗余功能。达到一定数量的特征时,分类器的准确度会增加,但有一个阈值,之后它开始下降。使用太多或太少的特征都会导致高方差和高偏差的问题。因此,搜索特征的最佳子集非常重要。
如果维度很大,即使用大量特征集,则还建议使用大型数据集。
消除高方差问题:
Use a smaller set of features.
要消除高偏差的问题:
Use additional features.
Add polynomial features.
单个数据集具有不同特征集的学习曲线
手动找出形成具有最高标准函数或成本函数J 的最佳子集的最大特征数是多少。
分支定界算法:
该算法通常用于监督学习算法。它遵循树结构来选择最佳的特征子集。
根节点包含所有特征,比如 n。中间子节点由比它们的父节点少 1 的特征组成,并且遵循该序列直到到达叶节点。一旦特征子集的大小被固定,比如说 x,那么树就可以用具有 x 个特征的叶节点来绘制。一旦到达叶节点,就会评估它的标准值并将其设置为边界值 b。在进一步评估其他分支时,如果其标准值超过 b,则将 b 更新为它,并将该分支扩展到其叶节点。如果其标准值不超过 b,则跳过该分支。最终,选择具有最高标准值的叶节点。
让我们通过一个例子来理解算法。

n = 4 且 x = 2 的分支定界树
在这里,父节点具有所有 4 个特征。在下一层,它被分支为 3 个比根节点少一个特征的子节点。这些节点中的每一个都再次分解为它们的子节点,并最终进入叶节点级别,其中叶节点是大小为 2 的最终特征子集,其中一个将被选择。
重要的是要注意这里节点的命名,因为这就是树的创建方式。节点 A 产生节点 B、C 和 D。一旦我们得到叶节点 B,我们首先评估它的标准值。这里,J = 20。所以,边界值,b 设置为 20。现在,生成节点 C,它的 J = 30 高于 b,因此 b 更新为 30,最佳特征子集更新到节点 C。接下来,生成节点 D,其 J = 16,小于 C 的 J = 16,因此 b 保持不变。
现在,创建了根节点的第二个子节点 E 并且它的 J = 10 再次小于 C,因此它不会进一步扩展,因为该子集组合无法为我们的模型提供更好的标准值。因此,不会创建节点 F,也不需要检查其值。这就是我们如何降低建模成本以及花在建模上的时间。
现在,生成了根节点的第三个也是最后一个子节点 G,它的 J = 35 高于 C,因此它被扩展了。节点 H 和节点 I 的 J 值分别为 28 和 20,两者都不高于 C,因此 {F2, F4} 是此问题的最佳特征子集。