📌 相关文章
- 数据结构-图的广度优先搜索算法
- 数据结构-图的广度优先搜索算法(1)
- 数据结构-深度优先遍历
- 数据结构中的线性搜索算法 (1)
- 深度优先搜索 - Python (1)
- A *搜索算法(1)
- A *搜索算法
- 深度优先搜索 - Python 代码示例
- 数据结构中的线性搜索算法 - 无论代码示例
- Python搜索算法
- Python搜索算法(1)
- python 深度优先搜索 - Python (1)
- Java搜索算法
- Java搜索算法(1)
- 深度优先搜索的应用(1)
- 深度优先搜索的应用
- python 深度优先搜索 - Python 代码示例
- 图的迭代深度优先遍历(1)
- 图的迭代深度优先遍历
- 图的深度优先搜索或 DFS(1)
- 图的深度优先搜索或 DFS
- 编译器设计中的深度优先排序
- 编译器设计中的深度优先排序(1)
- 二进制搜索算法 - Java (1)
- 线性搜索算法 c# (1)
- 二进制搜索算法 - Java 代码示例
- 线性搜索算法 c# 代码示例
- 人工智能的搜索算法(1)
- 人工智能搜索算法(1)
📜 数据结构-图的深度优先搜索算法
📅 最后修改于: 2020-10-15 01:08:16 🧑 作者: Mango
深度优先搜索(DFS)算法
深度优先搜索(DFS)算法从图G的初始节点开始,然后逐渐深入,直到找到目标节点或没有子节点的节点。然后,该算法从死角回溯到尚未完全开发的最新节点。
DFS中使用的数据结构是堆栈。该过程类似于BFS算法。在DFS中,导致未访问节点的边缘称为发现边缘,而导致已访问节点的边缘称为块边缘。
算法
- 步骤1: G中每个节点的SET STATUS = 1(就绪状态)
- 步骤2:将起始节点A推入堆栈并设置其STATUS = 2(等待状态)
- 步骤3:重复步骤4和5,直到堆栈为空
- 步骤4:弹出顶部节点N。对其进行处理并设置其STATUS = 3(处理状态)
- 步骤5:将所有处于就绪状态(状态STATUS = 1)的N个邻居推入堆栈,并设置其状态= 2(等待状态)[END OF LOOP]
- 步骤6:退出
范例:
考虑图G及其邻接表,如下图所示。通过使用深度优先搜索(DFS)算法,计算从节点H开始print图形的所有节点的顺序。
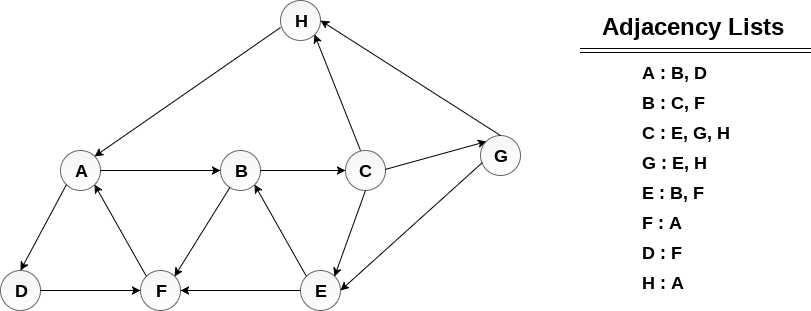
解决方案:
将H推入堆栈
STACK : H
弹出堆栈的顶部元素(即H),将其print出来并将H的所有邻居压入就绪状态的堆栈。
Print H
STACK : A
弹出堆栈(即A)的顶部元素,进行print,然后将A的所有邻居推入处于就绪状态的堆栈。
Print A
Stack : B, D
弹出堆栈的顶部元素,即D,进行print,然后将D的所有邻居推入处于就绪状态的堆栈。
Print D
Stack : B, F
弹出堆栈的顶部元素,即F,进行print,然后将F的所有邻居推入处于就绪状态的堆栈。
Print F
Stack : B
弹出栈顶,即B并推入所有邻居
Print B
Stack : C
弹出栈顶,即C并推入所有邻居。
Print C
Stack : E, G
弹出堆栈的顶部,即G并推入所有邻居。
Print G
Stack : E
弹出栈顶,即E并推入所有邻居。
Print E
Stack :
因此,堆栈现在变为空,并且遍历了图的所有节点。
图形的打印顺序为:
H → A → D → F → B → C → G → E