统计学是数学的重要分支,广泛用于经济学,商业,研究,调查等各种传统学科。在当今的数字时代,诸如数据科学和机器学习之类的新兴技术蓬勃发展。这些技术也以统计为中心。毕竟,统计数据全都与数据的收集,解释和表示有关。基本上,统计数据提供对数据的见解。
集中趋势测度
基本的统计概念是“集中趋势的度量”。此度量是用一个代表值汇总数据集的一种重要方法。此度量提供了数据点居中位置的粗略图片。常用的集中趋势度量是:
- 吝啬的
- 中位数
- 模式
吝啬的
“平均值”值称为数据集的平均值。计算平均值非常容易。
计算均值的步骤:
- 步骤1 。计算数据值的数量。设为n。
- 第二步。添加所有数据值。令总和为s。
- 第三步。平均值=所有数据值的总和/数据值的总数(n)
中位数
排序后的数据集的中间值称为中位数。考虑一个包含“ n”个元素的数据集。
计算中位数的步骤:
- 步骤1 。数据集以升序或降序排列。
- 第二步。如果数据集的数据值数量为奇数(n = odd),则将排序后的数据集的最中间值计算为中位数。换句话说,(n + 1)/ 2位的数据是数据集的中位数。
- 第三步。如果数据集具有偶数个数据值(n =偶数),则将两个中间值的平均值计算为中位数。即(n / 2)和{(n / 2)+ 1} th的均值是数据集的中位数。
模式
数据集中最频繁出现的值称为模式。
计算模式的步骤:
- 步骤1 。使用标记来识别每个数据值在数据集中出现多少次。
- 第二步。具有最大计数的数据值是数据集的模式。
例子
示例1.将5个孩子的体重(以kg为单位)分别为36、40、32、42、30。让我们计算均值,中位数和众数:
解决方案:
- Mean = (36 + 40 + 32 + 42 + 30)/5 = 180/5 = 36kg
- Median: Arrange the data in ascending order: 30, 32, 36, 40, 42 The middle value is 36. So, median = 36kg.
- Mode: 36 kg occurs most number of times, so mode = 36 kg
In this example, we saw that mean, median and mode are same.
示例2.考虑五名员工的年龄分别为30、30、32、38、60岁。计算集中趋势的度量。
解决方案:
- Mean = (30 + 30 + 32 + 38 + 60)/5 = 190/5 = 38 years
- Median: Arrange the data in ascending order: 30, 30, 32, 38, 60. The middlemost value is 32. So, median = 32 years
- Mode: 30 years occurs most number of ties, so mode = 30 years
In this example, we saw that mean, median and mode have different values.
示例3.五个学生A,B,C,D,E参加考试,分别获得80分,95分,90分,85分和100分。找到意思了吗?
解决方案:
Total number of students = 5
Sum of marks = 80 + 95 + 90 + 85 +100 = 450
Mean = Sum of marks/total number of students
= 450/5 = 90 marks
示例4.一名击球手在六场比赛中平均得分为48次。如果他在五场比赛中的得分分别为51、45、46、44和49。在第六场比赛中找到他的得分了吗?
解决方案:
Total number of matches = 6
Assume his score in sixth match = x runs
Average = 48 runs
So, (51 + 45 + 46 + 44 + 49 + x)/6 = 48
So, 235 + x = 48 x 6 = 288 = 235 + x = 288
x = 288 – 235 = 53
He scores 53 runs in sixth match.
示例5.五个连续奇数的平均值为15。找到数字了吗?
解决方案:
Assume the smallest odd number be x.
So, the other numbers are x + 2, x + 4, x + 6, x + 8
Given that the average = 15.
So, (x + x + 2 + x + 4 + x + 6 + x + 8)/5 = 15
= 5x + 20 = 75
= 5x = 55
x = 55/5 = 11
So, the numbers are 11, 13, 15, 17, 19
例6.一位老师报告说,在20名学生中,平均得分为35分。后来她意识到一个学生的分数实际上是45分,但错误地,她的分数是25分。找到班上正确的平均分数。
解决方案:
Mean = 35
Number of students = 20
So, total sum of marks = 32 × 20 = 700
Corrected sum of marks = 700 – 25 + 45 = 720
So, average = 720/20 = 36
Correct mean = 36 marks
分布和均值
数据集中的极值极大地影响了均值。如果数据集是对称的,则平均值恰好位于中心。但是,在偏斜分布中,平均值会偏离中心。
情况1:对称分布
考虑对称分布。假设组织中员工的月薪为30k,40k,35k,32k,38k卢比。
平均值=(30 + 40 + 35 + 32 + 38)/ 5 = 175/5 = 35k卢比
中位数:按升序对数据进行排序。 30k,32k,35k,38k,40k。由于排序后的数据集中的最中间值为35k。我们可以得出结论,工资中位数= 35k卢比。没有清除模式,因为所有数据值都出现相同的次数。
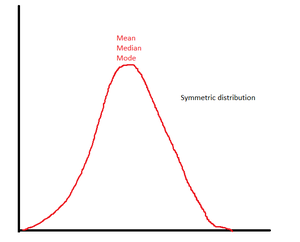
均值=中位数=对称分布中的众数
情况2:分布偏斜
在一个值与其他值异常不同的偏斜分布中,平均值会急剧变化。

平均值>右偏分布的中位数

平均值<左偏分布的中位数
让我们假设一个场景,在这个场景中,一名员工得到了晋升,而他的薪水也得到了惊人的提高。假设他的薪水从每月38k变为每月85k。这是右偏的情况,因为数据值已向右移动。根据该图,我们期望平均值应大于中位数。
让我们计算平均值和中位数的新值
新数据集的值分别为30、40、35、32、88
平均值=(30 + 40 + 35 + 32 + 88)= 225/5 = 45,000卢比
中位数:
按升序对数据进行排序。
30k,32k,35k,40k,88k
由于排序后的数据集中的中间值是35k,因此我们可以得出结论,工资中位数= 35k卢比。因此,我们看到平均值有所变化,但中位数仍为35k卢比。显然,平均值对数据的变化极为敏感。但是,中位数相对稳定。
中央倾向的最佳量度
- 均值是数据正态分布时集中趋势的首选度量。
- 数据偏斜时,中位数是集中趋势的最佳度量。
- 在处理名义变量时,该模型是集中趋势的最佳度量。
结论
- 均值,中位数和众数是集中趋势的最重要度量。完整的数据集可以由这些值表示。
- 均值,中位数和众数不必具有相同的值。
- 均值对极端数据值敏感。
- 将偏态分布的平均值作为数据集的真实代表是不明智的。
- 中位数是理解偏态分布的更好方法。
- 除非所有数据值均为零,否则平均值和中位数不能为零。但是,数据集中可能没有模式。