R 中的 Beta 分布
统计中的分布是一个函数,它显示变量的可能值以及它们在特定实验或数据集中出现的频率。 Beta 分布是一种概率分布,表示数据集的所有可能结果。 Beta 分布基本上显示概率的概率,其中 α 和 β 可以取任何取决于成功/失败概率的值。
Beta 分布的概率密度函数的一般公式为:

在哪里 ,
- p 和 q 是形状参数
- a 和 b 是下限和上限
- a≤x≤b
- p,q>0
- B(p,q) 是 beta函数
为了具体了解 R 中的 beta 分布,我们将了解 beta 函数。 Beta函数是 beta 分布的一个组成部分(R 中的 beta函数可以使用 beta (a,b)函数),其中包括这些 dbeta 、 pbeta 、 qbeta 和 rbeta ,它们是 Beta 分布的函数。
Beta函数定义为:

a = 0 且 b = 1 的情况称为标准 Beta 分布。因此标准的 beta 分布是:

通过β分布,我们还可以找出集中趋势的度量,如均值、中值模式,以及方差等统计离散的度量。
为什么是 Beta 发行版?
为什么我们实际上可能想要选择 beta 分布来指定关于 theta 的先验知识,主要原因之一是该分布定义在 [0,1] 的范围内,因此当我们使用 beta 分布时,使用 beta 分布是一种非常自然的分布正在谈论概率,我们想要指定关于某事物发生概率的先验知识。
Beta 分布的信念范围
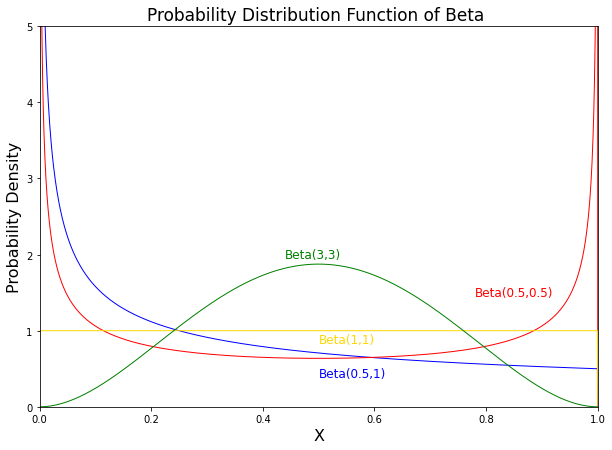
信念的范围是我们实际上可以通过改变 p 和 q 的参数即形状参数来定义一个很大的范围。
让我们举一个例子来更好地理解它。
| S.no. | p | q |
|---|---|---|
1 | 0.5 | 0.5 |
2 | 0.5 | 1 |
3 | 1 | 1 |
4 | 3 | 3 |
让我们从 p 和 q 都是 0.5 开始。我们把 1/2 放在这个等式中:

在这之后它变成
那么我们也可以这样写这个方程:

因此,从上面的等式我们观察到,如果 x 变为 0 或 1 ,则我们有无穷大。然后我们将计算所有 p 和 q 值的点。 Beta 分布的概率分布函数(Probability distribution 函数)由上述观察可以形成三种形状:具有渐近端的 U 形、钟形、严格递增/递减甚至直线。当您更改 p 或 q 的值时,分布的形状也会发生变化。
因此,图表将如下所示:
现在,让我们在 R 中绘制 Beta 分布函数,以便更好地理解它们。首先,绘制 Beta 密度,然后绘制所有其他函数。
β密度
用于绘制我们知道的 beta 密度,它将位于 (0,1) 的范围之间。我们在图中使用了一个 dbeta 和 plot函数。
Syntax: dbeta(xvalues,alpha,beta)
示例 1:在这里,我们可以观察 Beta Density(1,1) 的图,我们可以观察到 0 和 1 之间的均匀分布。
R
# Creating the Sequence
gfg = seq(0, 1, by = 0.1)
# Plotting the beta density
plot(gfg, dbeta(gfg, 1,1), xlab="X",
ylab = "Beta Density", type = "l",
col = "Red")R
# Creating the Sequence
gfg = seq(0,1, by=0.1)
# Case 2
plot(gfg, dbeta(gfg, 2,1), xlab="X",
ylab = "Beta Density", type = "l",
col = "Red")R
# Creating the Sequence
gfg = seq(0,1, by=0.1)
# Case 3
plot(gfg, dbeta(gfg, 2,2), xlab = "X",
ylab = "Beta Density", type = "l",
col = "Red")R
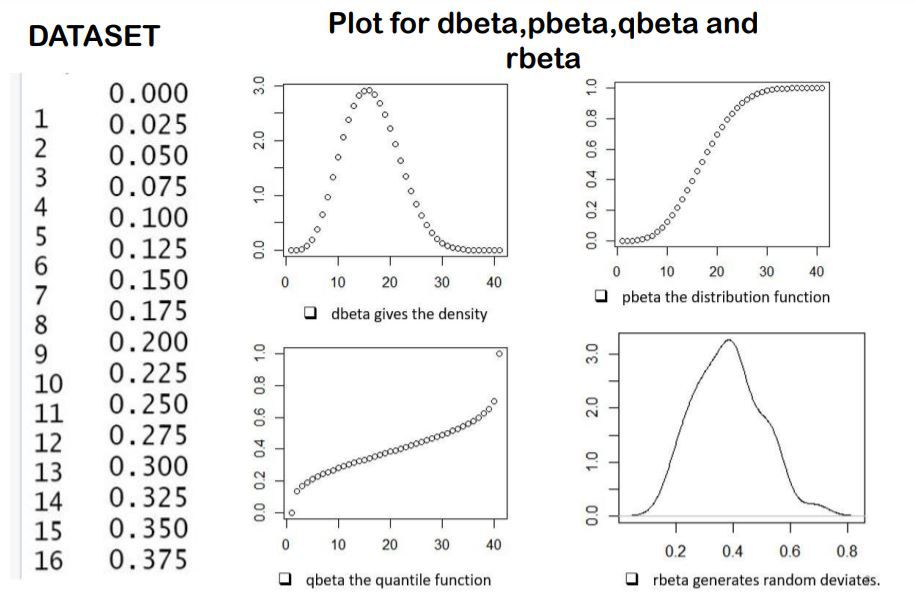
# The Beta Distribution
plr.data <- data.frame(
player_avg <- c(seq(0, 1, by = 0.025)),
stringsAsFactors = FALSE
)
# Print the data frame.
print(plr.data)
print(plr.data$player_avg)
by1 <- dbeta(plr.data$player_avg, shape1 = 5, shape2 = 8)
par(mar = rep(2,4))
plot(by1)
# Cummilative distribution function
by2<- pbeta(plr.data$player_avg, shape1 = 4, shape2 = 6)
par(mar = rep(2,4))
plot(by2)
# Inverse Cummilative distribution function
by3 <- qbeta(plr.data$player_avg, shape1 = 4, shape2 = 6)
par(mar = rep(2,4))
plot(by3)
b4 <- rbeta(plr.data$player_avg, shape1 = 5, shape2 = 8)
par(mar = rep(2,4))
plot(density(b4), main = "Rbeta Plot")输出:
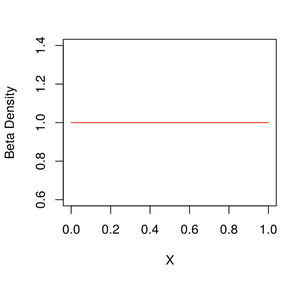
Beta 密度图 (1,1)
示例 2:在这里,我们可以观察到 Beta Density(2,1) 的绘图,我们可以观察到线性增加的函数,在上面的绘图中,我们可以看到这些点更有可能接近 1 而不是 0 并且它们上升以成比例的方式。如果我们只是将图从 (2,1) 更改为 (1,2),我们可以看到这些点更有可能接近 0 而不是 1。
电阻
# Creating the Sequence
gfg = seq(0,1, by=0.1)
# Case 2
plot(gfg, dbeta(gfg, 2,1), xlab="X",
ylab = "Beta Density", type = "l",
col = "Red")
输出:
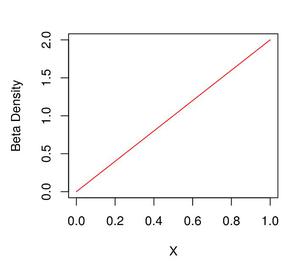
Beta 密度图 (2,1)
示例 3:在这里,我们可以观察 Beta Density(2,2) 的绘图,其中我们可以观察到接近 0 和 1 之间的二次函数值,但最有可能具有接近 1/2 的值。
电阻
# Creating the Sequence
gfg = seq(0,1, by=0.1)
# Case 3
plot(gfg, dbeta(gfg, 2,2), xlab = "X",
ylab = "Beta Density", type = "l",
col = "Red")
输出:
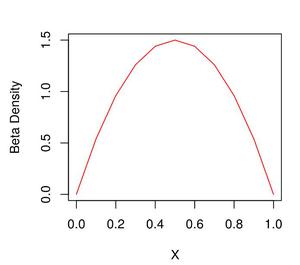
Beta 密度图 (2,2)
累积分配函数
您可以参考此链接了解 Beta 分布函数的功能。
在我们的例子中,我们拥有的数据显示了可以取 0 到 1 之间的任何数值的平均值,如您所见,0,1 是上述代码第 3 行中的参数,因此通过 beta 分布,我们描述了一个值在 0 到 1 之间的有界连续分布,主要模拟随机实验成功概率的不确定性,在我们的例子中,它是具有特定平均值的概率的概率。
因此,它经常用于与比例、频率或百分比相关的不确定性问题。
电阻
# The Beta Distribution
plr.data <- data.frame(
player_avg <- c(seq(0, 1, by = 0.025)),
stringsAsFactors = FALSE
)
# Print the data frame.
print(plr.data)
print(plr.data$player_avg)
by1 <- dbeta(plr.data$player_avg, shape1 = 5, shape2 = 8)
par(mar = rep(2,4))
plot(by1)
# Cummilative distribution function
by2<- pbeta(plr.data$player_avg, shape1 = 4, shape2 = 6)
par(mar = rep(2,4))
plot(by2)
# Inverse Cummilative distribution function
by3 <- qbeta(plr.data$player_avg, shape1 = 4, shape2 = 6)
par(mar = rep(2,4))
plot(by3)
b4 <- rbeta(plr.data$player_avg, shape1 = 5, shape2 = 8)
par(mar = rep(2,4))
plot(density(b4), main = "Rbeta Plot")
输出: