机器学习中有两种类型的监督学习算法用于分类。
- 判别学习算法
- 生成学习算法
判别式学习算法包括逻辑回归,感知器算法等,它们试图在学习过程中找到不同类别之间的决策边界。例如,给定分类问题以预测患者是否患有疟疾,判别学习算法将尝试创建分类边界以分离两种类型的患者,并且在引入新示例时会检查该边界的哪一侧该示例在于对其进行分类。这样的算法尝试对P(y | X)建模,即给定数据样本的特征集X,它属于“ y”类的概率是多少。
另一方面,生成学习算法采用了不同的方法,它们试图单独捕获每个类的分布,而不是在类之间找到决策边界。考虑前面的示例,生成学习算法将分别查看感染患者和健康患者的分布,并尝试分别了解分布的每个特征,在引入新示例时,将其与两个分布进行比较,该数据示例将被分配最多。这样的算法尝试在此处为给定的P(y)建模P(X | y) ,P(y)被称为类Prior 。
使用贝叶斯定理对生成学习算法的预测如下:

仅使用特定类的P(X | y)和P(y)的值,我们就可以计算P(y | X),即给定数据样本的特征,它属于“ y”类的概率是多少。
高斯判别分析是一种生成型学习算法,为了捕获每个类别的分布,它尝试将高斯分布分别拟合到数据的每个类别。下图描绘了判别式学习算法和生成式学习算法之间的区别。在生成学习算法的情况下,如果预测的概率位于与类别对应的轮廓的中心附近,并且随着远离轮廓的中心而降低,则预测的可能性会降低。
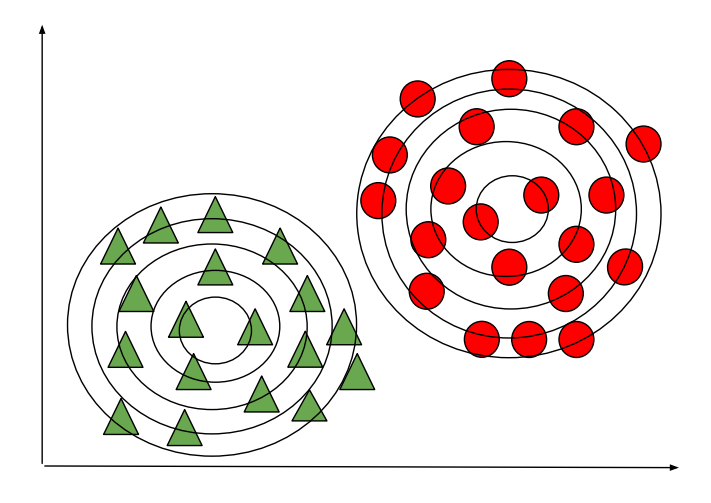
生成学习算法(GDA)

判别学习算法
让我们考虑一个二元分类问题,使得所有数据样本都是IID(独立且相同地分布),因此,为了计算P(X | y),我们可以使用多元高斯分布为每个单独的类形成概率密度函数。并且为了计算每个类别的P(y)或类别优先级,我们可以使用Bernoulli分布,因为二进制分类中的所有数据样本的取值可以为1或0。
因此,可以分别使用高斯分布和伯努利分布的一般形式来定义数据样本之前的概率分布和类别:


为了将概率分布视为上述参数的函数,我们可以定义一个似然函数,该函数等于每个数据样本的概率分布和类优先级的乘积(取概率的乘积是合理的,因为所有数据样本被视为IID)。

根据最大似然估计的原理,我们必须以最大化方程4中给出的概率函数的方式来选择参数的值。要做到最大化似然函数,我们可以最大限度地数似然函数是严格递增函数,这样来代替。


在以上等式中,函数“ 1 {condition}”是指示符函数,如果条件为true,则返回1,否则返回0。例如,仅当该数据样本的类别为1时,1 {y = 1}才会返回1。 1否则类似地返回0,在1 {y = 0}的情况下,仅当该数据样本的类为0时才返回1,否则它返回0。
可以将获得的参数的值插入等式1、2和3中,以找到所有数据样本之前的概率分布和分类。获得的这些值可以进一步乘以找到等式4中给出的似然函数。如前所述,似然函数即P(X | y).P(y)可以插入贝叶斯公式中以预测P(y | X)(即针对给定特征’预测数据样本的类’ y ‘ X ‘)。
NOTE: The data samples in this model is considered to be IID which is an assumption made about the model, Gaussian Discriminant Analysis will perform poorly if the data is not a Gaussian distribution, therefore, it is always suggested visualizing the data to check if it has a normal distribution and if not attempts can be made to do so by using methods like log-transform etc. (Do not confuse Gaussian Discriminant Analysis with Gaussian Mixture model which is an unsupervised learning algorithm).
因此,如果我们对数据分布的基本假设是正确的,那么高斯判别分析在少量数据(例如几千个示例)上的效果很好,并且与Logistic回归相比可以更健壮
参考: http : //cs229.stanford.edu/notes2020spring/cs229-notes2.pdf