提前停止正则化
正则化是一种回归,其中修改学习算法以减少过度拟合。这可能会导致更高的偏差,但与非正则化模型相比会导致更低的方差,即增加训练算法的泛化。
在一般的学习算法中,数据集被划分为训练集和测试集。在算法的每个 epoch 之后,在理解数据集后相应地更新参数。最后,将这个训练好的模型应用于测试集。通常,与测试集误差相比,训练集误差会更小。这是因为过拟合导致算法记住训练数据并在训练集上产生正确的结果。因此,该模型对训练集高度排斥,并且无法为包括测试集在内的其他数据集产生准确的结果。在这种情况下使用正则化技术来减少过度拟合并提高模型在任何通用数据集上的性能。由于其简单性和有效性,提前停止是一种流行的正则化技术。
通过将数据集划分为训练集和测试集,然后在训练集上使用交叉验证,或者将数据集划分为训练集、验证集和测试集,可以通过提前停止进行正则化,在这种情况下不需要交叉验证。这里分析第二种情况。在提前停止中,算法使用训练集进行训练,停止训练的点由验证集确定。分析了训练误差和验证误差。训练误差稳步下降,而验证误差下降,直到某一点,然后增加。这是因为在训练期间,学习模型开始过度拟合训练数据。这导致训练误差减少而验证误差增加。因此,如果使用给出最小验证集误差的参数,则可以获得具有更好验证集误差的模型。每次验证集上的错误减少时,都会存储模型参数的副本。当训练算法终止时,最终返回这些给出最小验证集错误的参数,而不是最后修改的参数。
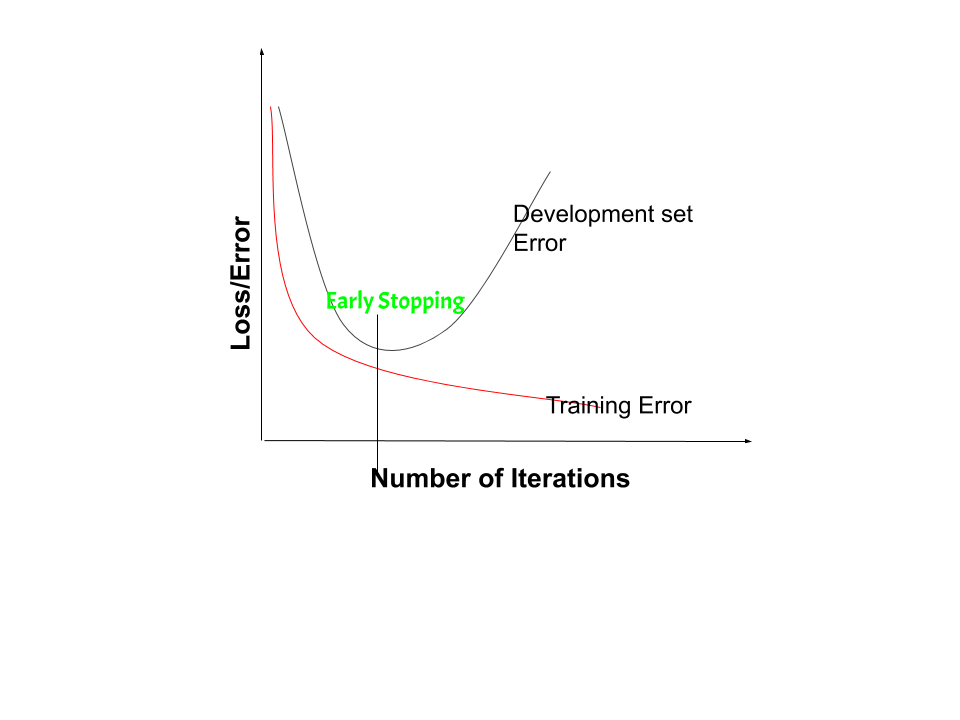
在早期停止正则化中,当模型在验证集上的性能变得更糟时,我们停止训练模型 - 增加损失或降低准确性或评分指标的值变差。通过将训练数据集和验证数据集上的误差绘制在一起,两个误差都会随着迭代次数的增加而减少,直到模型开始过度拟合为止。在此之后,训练误差仍然减少,但验证误差增加。因此,即使在这一点之后继续训练,提前停止本质上会返回此时使用的参数集,因此等效于在该点停止训练。因此,返回的最终参数将使模型具有低方差和更好的泛化能力。停止训练时的模型将比训练误差最小的模型具有更好的泛化性能。提前停止可以被认为是隐式正则化,与通过权重衰减的正则化相反。这种方法也很有效,因为它需要较少的训练数据,而这并不总是可用的。由于这个事实,与其他正则化方法相比,提前停止需要更少的训练时间。多次重复提前停止过程可能会导致模型过拟合验证数据集,就像在训练数据的情况下发生过拟合一样。
用于训练模型的迭代次数可以被视为超参数。然后模型必须为这个超参数找到一个最佳值(通过超参数调整)以获得学习模型的最佳性能。