描述性统计
在描述性统计中,我们借助各种具有代表性的方法来描述我们的数据,例如使用图表、图形、表格、Excel 文件等。在描述性统计中,我们以某种方式描述我们的数据并以有意义的方式呈现它,以便它可以很容易理解。大多数情况下,它是在小数据集上执行的,这种分析有助于我们根据当前的发现预测一些未来的趋势。用于描述数据集的一些度量是集中趋势的度量和可变性或离散度的度量。
描述性统计的类型:
- 集中趋势的度量
- 可变性的测量

集中趋势的度量:
它以单个值表示整个数据集。它为我们提供了中心点的位置。集中趋势的三个主要指标:
- 意思是
- 模式
- 中位数

- 意思是:
它是观察的总和除以观察的总数。它也被定义为平均值,即总和除以计数。

其中,n = 项数
Python代码在Python中查找均值import numpy as np # Sample Data arr = [5, 6, 11] # Mean mean = np.mean(arr) print("Mean = ", mean)输出 :
Mean = 7.333333333333333 - 模式:
它是给定数据集中频率最高的值。如果所有数据点的频率相同,则数据集可能没有众数。此外,如果我们遇到两个或多个具有相同频率的数据点,我们可以有多个模式。在Python中查找模式的代码
from scipy import stats # sample Data arr =[1, 2, 2, 3] # Mode mode = stats.mode(arr) print("Mode = ", mode)输出:
Mode = ModeResult(mode=array([2]), count=array([2])) - 中位数:
它是数据集的中间值。它将数据分成两半。如果数据集中元素的数量是奇数,则中心元素是中值,如果是偶数,则中值将是两个中心元素的平均值。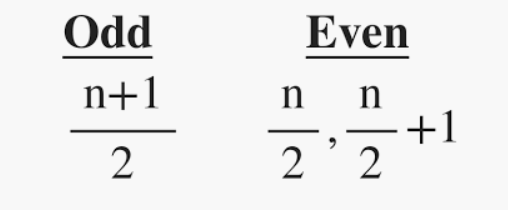
其中,n = 项数
查找中位数的Python代码import numpy as np # sample Data arr =[1, 2, 3, 4] # Median median = np.median(arr) print("Median = ", median)输出:
Median = 2.5可变性的测量:
可变性的度量被称为数据的传播或我们的数据分布的好坏。最常见的可变性测量是:- 范围
- 方差
- 标准差

- 范围:
该范围描述了我们数据集中最大和最小数据点之间的差异。范围越大,数据的传播越多,反之亦然。
Range = Largest data value – smallest data value
查找范围的Python代码
import numpy as np # Sample Data arr = [1, 2, 3, 4, 5] #Finding Max Maximum = max(arr) # Finding Min Minimum = min(arr) # Difference Of Max and Min Range = Maximum-Minimum print("Maximum = {}, Minimum = {} and Range = {}".format( Maximum, Minimum, Range))输出:
Maximum = 5, Minimum = 1 and Range = 4 - 方差:
它被定义为与平均值的平均平方偏差。它是通过找出每个数据点与平均值之间的差异(也称为均值)来计算的,将它们平方,将它们全部相加,然后除以我们数据集中存在的数据点的数量。
其中 N = 项数
u = 平均值
查找方差的Python代码import statistics # sample data arr = [1, 2, 3, 4, 5] # variance print("Var = ", (statistics.variance(arr)))输出:
Var = 2.5 - 标准偏差:
它被定义为方差的平方根。它是通过找到平均值来计算的,然后从平均值中减去每个数字,这也称为平均值,然后对结果进行平方。将所有值相加,然后除以平方根后的项数。
其中 N = 项数
u = 平均值
执行标准偏差的Python代码:import statistics # sample data arr = [1, 2, 3, 4, 5] # Standard Deviation print("Std = ", (statistics.stdev(arr)))输出:
Std = 1.5811388300841898
参考 :
大数据维基百科
公式 - 范围: