- Python|使用 Pandas.drop() 从 DataFrame 中删除行列(1)
- Python | 使用Pandas.drop()从DataFrame删除行列(1)
- Python Pandas DataFrame
- Python Pandas DataFrame(1)
- Pandas DataFrame.drop_duplicates()(1)
- Pandas DataFrame.drop_duplicates()
- 从 Pandas DataFrame 中删除行列表(1)
- 从 Pandas DataFrame 中删除行列表
- Python中的 pandas.DataFrame.T()函数(1)
- Python中的 pandas.DataFrame.T()函数
- 删除 Pandas DataFrame 的最后 n 行
- 删除 Pandas DataFrame 的最后 n 行(1)
- Python | Pandas 数据 DataFrame
- Python | Pandas 数据 DataFrame(1)
- drop na pandas - Python (1)
- 删除列 pandas - Python (1)
- 删除 pandas 中的列 - Python (1)
- 删除 pandas 列 - Python (1)
- pandas 删除列 - Python (1)
- drop na pandas - Python 代码示例
- 从 Pandas DataFrame 中删除一列(1)
- 从 Pandas DataFrame 中删除一列
- 如何删除 R DataFrame 中的行?(1)
- 如何删除 R DataFrame 中的行?
- 如何删除 R DataFrame 中的行?
- 从多索引 Pandas Dataframe 中删除特定行
- 从多索引 Pandas Dataframe 中删除特定行(1)
- 计算 Pandas Dataframe 中的值
- 计算 Pandas Dataframe 中的值(1)
📅 最后修改于: 2020-04-22 02:55:41 🧑 作者: Mango
Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。Pandas是其中的一种,使导入和分析数据更加容易。
Pandas为数据分析人员提供了一种使用.drop()方法删除和过滤数据帧的方法。使用此方法,可以使用索引标签或列名删除行或列。
语法:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=’raise’)参数:
labels:引用行或列名称的字符串或字符串列表。
axis:整数或字符串值,“ 0″用于行,“ 1″用于列。
index or columns:单个标签或列表。index或column是轴的替代方法,不能一起使用。
level:用于指定数据帧具有多个级别索引。
inplace:如果为True,则在原始数据框中进行更改。
errors:如果列表中的任何值都不存在,则忽略错误,并在errors =’ignore’时删除其余值
返回类型:具有丢弃值的数据框
要下载代码中使用的CSV,请点击此处。
示例1:按索引标签删除行
在代码中,传递了索引标签列表,并使用.drop()方法删除了与这些标签对应的行。
# 导入pandas模块
import pandas as pd
# 从csv文件制作数据帧
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的值
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace = True)
# 打印
data输出:
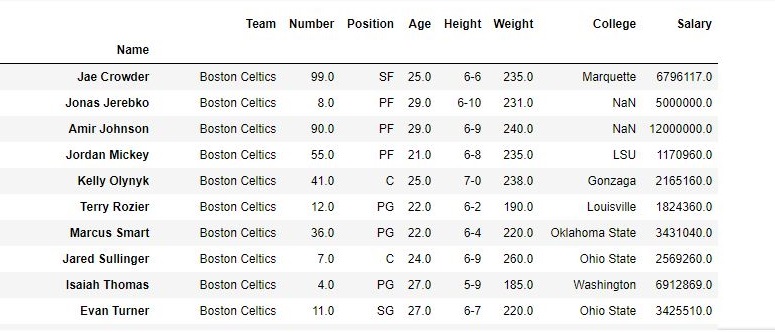
如输出图像所示,新输出没有传递的值。由于inplace为True,因此删除了这些值,并在原始数据框中进行了更改。
删除值之前的:


数据帧-删除值之后的数据帧:

Example#2:删除具有列名的列
在他的代码中,传递的列使用列名删除。axis参数保持为1,因为1引用了列。
# 导入pandas模块
import pandas as pd
# 从csv文件制作数据帧
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的列
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# 打印
data输出:
如输出图像所示,新的输出没有传递的列。由于将axis设置为1,所以这些值将被删除,并且由于inplace为True,因此在原始数据帧中进行了更改。
删除列之前的:
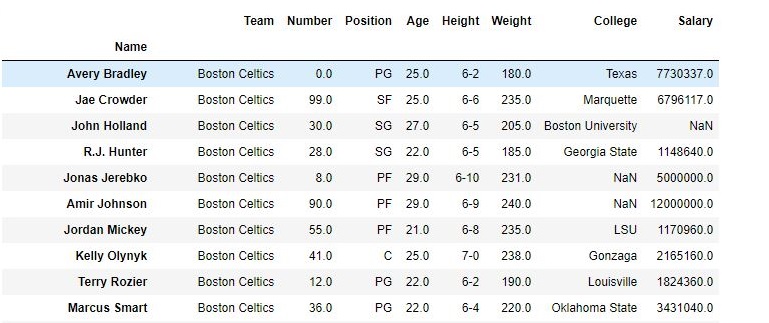

数据帧-删除列之后的数据帧:

