如何在Python中执行邓恩检验
如果 Kruskal-Wallis 检验产生统计上显着的结果,则应使用Dunn 检验来确定哪些组是不同的。在您的 ANOVA 显示三个或更多均值的显着差异后,您可以应用邓恩检验来确定哪些特定均值与其他均值不同。 Dunn 的多重比较检验是一种非参数事后非参数检验,它不假定您的数据来自某个分布。
要执行 duns 测试,用户需要调用 scikit-posthocs 库中的 posthoc_dunn()函数。
posthoc_dunn()函数:
Syntax:
scikit_posthocs.posthoc_dunn(a, val_col: str = None, group_col: str = None, p_adjust: str = None, sort: bool = True)
Parameters:
- a : it’s an array type object or a dataframe object or series.
- group_col : column of the predictor or the dependent variable
- p_adjust: P values can be adjusted using this method. it’s a string type possible values are :
- ‘bonferroni’
- hommel
- holm-sidak
- holm
- simes-hochberg and more…
Returns: p-values.
安装 posthocs 库的语法:
pip install scikit-posthocs
这是一个假设检验,两个假设如下:
- 零假设:给定样本具有相同的中位数
- 备择假设:给定样本具有不同的中位数。
在本例中,我们导入包,读取 iris CSV 文件,并使用 posthoc_dunn()函数进行 dunns 测试。对三种植物的萼片宽度进行了邓恩检验。
单击此处查看和下载 CSV 文件。
Python3
# importing packages and modules
import pandas as pd
import scikit_posthocs as sp
# reading CSV file
dataset= pd.read_csv('iris.csv')
# data which contains sepal width of the three species
data = [dataset[dataset['species']=="setosa"]['sepal_width'],
dataset[dataset['species']=="versicolor"]['sepal_width'],
dataset[dataset['species']=="virginica"]['sepal_width']]
# using the posthoc_dunn() function
p_values= sp.posthoc_dunn(data, p_adjust = 'holm')
print(p_values)Python3
p_values > 0.05输出:

- 对于第 1 组和第 2 组之间的差异,调整后的 p 值为 3.247311e-14
- 对于第 2 组和第 3 组之间的差异,调整后的 p 值为 1.521219e-02
我们进一步检查 p_values 是否高于显着性水平。 false 表示两组具有统计显着性或拒绝原假设。
Python3
p_values > 0.05
输出:
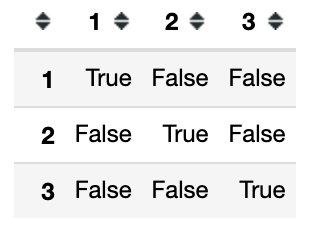
在本例中,我们将显着性水平设为 0.05。没有两组(物种)具有统计学意义,因为没有两组的 p_value 超过 0.05。因此,我们可以说原假设为假,而备择假设为真。