在Python中使用 Plotly 绘制森伯斯特图
Plotly是一个Python库,用于设计图形,尤其是交互式图形。它可以绘制各种图形和图表,如直方图、条形图、箱线图、散布图等等。它主要用于数据分析和财务分析。 plotly 是一个交互式可视化库。
Plotly 中的森伯斯特情节
森伯斯特图从根到叶逐渐可视化分层数据。根部从中心开始,喷出添加到外环。层次结构的每一级由一个环或最内圈的圆圈表示,进一步的环被分成表示数据点的切片,切片的大小表示数据值。
Syntax: plotly.express.sunburst(data_frame=None, names=None, values=None, parents=None, path=None, ids=None, color=None, color_continuous_scale=None, range_color=None, color_continuous_midpoint=None, color_discrete_sequence=None, color_discrete_map={}, hover_name=None, hover_data=None, custom_data=None, labels={}, title=None, template=None, width=None, height=None, branchvalues=None, maxdepth=None)
Parameters:
data_frame: This argument needs to be passed for column names (and not keyword names) to be used.
names: Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used as labels for sectors.
values: Either a name of a column in data_frame or a pandas Series or array_like object. Values from this column or array_like are used to set values associated to sectors.
parents: Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used as parents in sunburst and treemap charts.
path: Either names of columns in data_frame, or pandas Series, or array_like objects List of columns names or columns of a rectangular dataframe defining the hierarchy of sectors, from root to leaves.
ids: Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used to set ids of sectors
例子:
Python3
import plotly.express as px
df = px.data.iris()
fig = px.sunburst(df, path=['sepal_length',
'sepal_width',
'petal_length'],
values='petal_width')
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.sunburst(df, path=['day', 'sex'],
values='total_bill')
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.sunburst(df, path=['day', 'sex'],
values='total_bill', color='total_bill')
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.sunburst(df, path=['day', 'sex'],
values='total_bill', color='time')
fig.show()Python3
import plotly.express as px
import pandas as pd
A = ["A", "B", "C", "D", None, "E",
"F", "G", "H", None]
B = ["A1", "A1", "B1", "B1", "N",
"A1", "A1", "B1", "B1", "N"]
C = ["N", "N", "N", "N", "N",
"S", "S", "S", "S", "S"]
D = [1, 13, 21, 14, 1, 12, 25, 1, 14, 1]
df = pd.DataFrame(
dict(A=A, B=B, C=C, D=D)
)
fig = px.sunburst(df, path=['C', 'B', 'A'], values='D')
fig.show()输出:
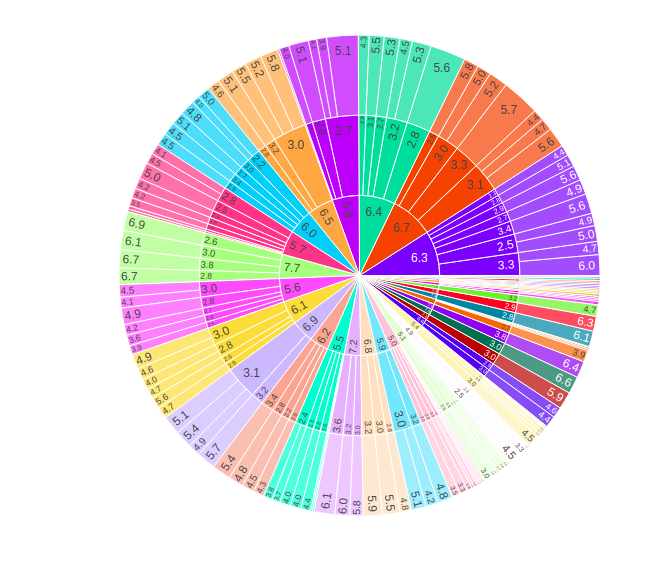
绘制分层数据
矩形数据框表示分层数据,其中不同的列对应于不同的层次结构。绘制这样的列路径参数被使用。路径参数采用 data_frame 或 pandas Series 中的列名称,或 array_like 对象,列名称列表或定义扇区层次结构的矩形数据框的列,从根到叶。
注意:当 id 或父母与路径一起传递时,会引发错误。
例子:
Python3
import plotly.express as px
df = px.data.tips()
fig = px.sunburst(df, path=['day', 'sex'],
values='total_bill')
fig.show()
输出:
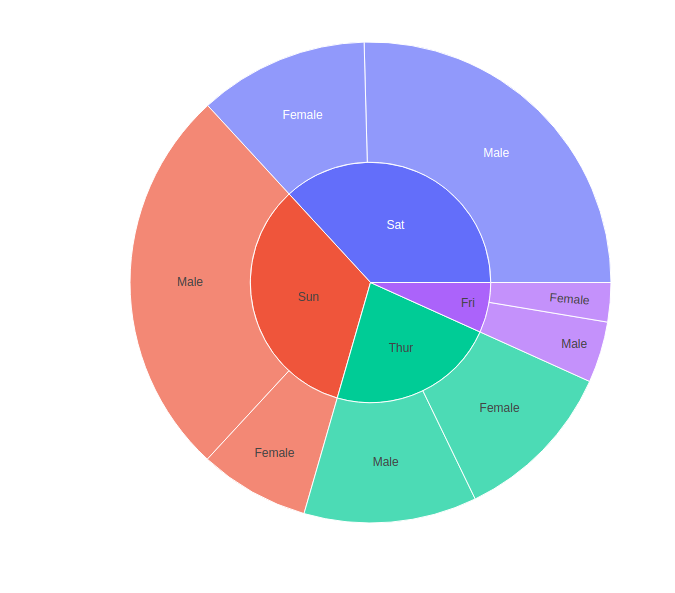
使用连续颜色参数绘制分层数据
如果传递了颜色参数,则节点的颜色将通过其子节点的值计算为其子节点的平均颜色值。
例子:
Python3
import plotly.express as px
df = px.data.tips()
fig = px.sunburst(df, path=['day', 'sex'],
values='total_bill', color='total_bill')
fig.show()
输出:
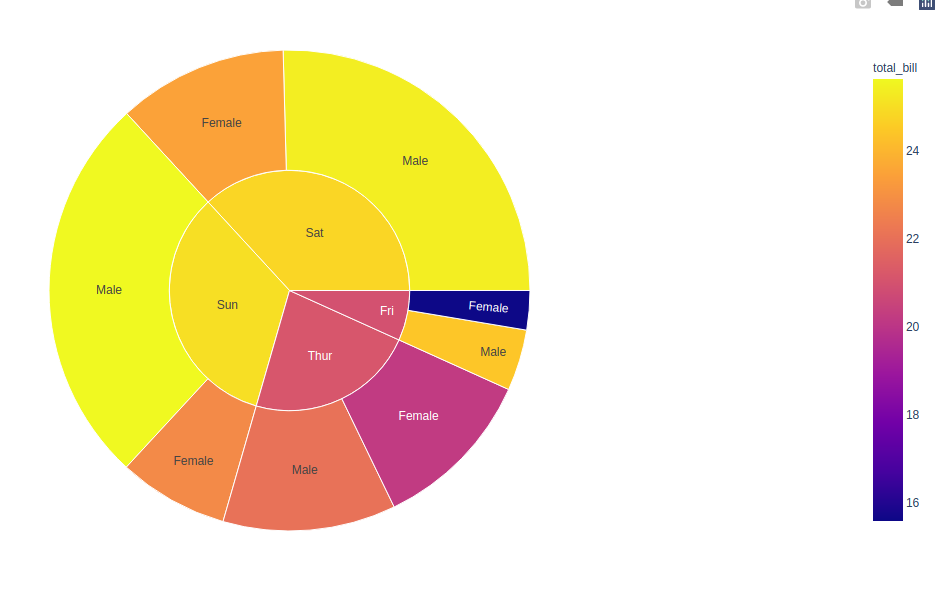
使用离散颜色参数绘制分层数据
当将非数值数据传递给颜色参数时,将使用离散数据。如果一个扇区的颜色列对其所有子项具有相同的值,则使用相应的颜色,否则将使用相同的离散颜色的第一种颜色。
例子:
Python3
import plotly.express as px
df = px.data.tips()
fig = px.sunburst(df, path=['day', 'sex'],
values='total_bill', color='time')
fig.show()
输出:

绘制具有缺失值的分层数据
如果数据集的形状不是完全矩形,则应将缺失值视为无。父母的所有条目都必须是叶子,否则将引发 valueError。
例子:
Python3
import plotly.express as px
import pandas as pd
A = ["A", "B", "C", "D", None, "E",
"F", "G", "H", None]
B = ["A1", "A1", "B1", "B1", "N",
"A1", "A1", "B1", "B1", "N"]
C = ["N", "N", "N", "N", "N",
"S", "S", "S", "S", "S"]
D = [1, 13, 21, 14, 1, 12, 25, 1, 14, 1]
df = pd.DataFrame(
dict(A=A, B=B, C=C, D=D)
)
fig = px.sunburst(df, path=['C', 'B', 'A'], values='D')
fig.show()
输出:
